CLOSED
Using pySpark with Google Colab & Spark 3.0 preview - Meetup in Milan, 11th December 2019
Using pySpark with Google Colab & Spark 3.0 preview - Meetup in Milan, 11th December 2019
3D Pose Estimation and Tracking from RGB-D

Hi everyone, this is my first article so I am going to introduce myself.
My name is Lorenzo Graziano and I work as Data Engineer at Agile Lab, an Italian company focused on scalable technologies and AI in production.
Thanks to Agile Lab, during the last two years I attended a 2nd level Master’s Degree in Artificial Intelligence at the University of Turin. In this post, I am going to present part of the work done during this awesome experience.
The project described in this post falls within the context of computer vision, the Artificial Intelligence branch that deals with high-level understanding of images and video sequences.
In many real-world applications, such as autonomous navigation, robotic manipulation and augmented reality, it is essential to have a clear idea of how the environment is structured. In particular, recognizing the presence of objects and understanding how they are positioned and oriented in space is extremely important. In fact, this information enables the interaction with the environment, which otherwise would be ineffective.



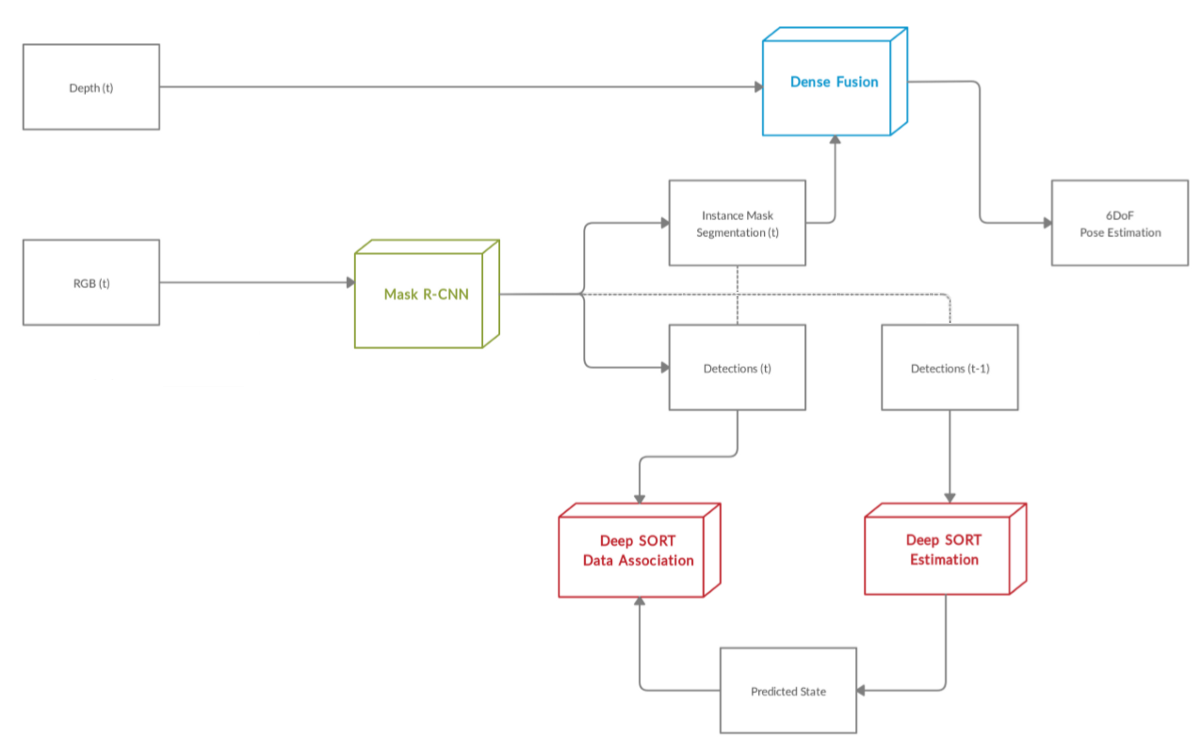
The goal of this project is to create an architecture capable of monitoring the position and orientation of different instances of objects belonging to different classes within a video sequence bearing depth information (RGB-D signal). The result will be a framework suitable for use in different types of applications based on artificial vision.
The central part of the architecture is clearly the one intended for the 6D pose estimation. After evaluating the performance of various solutions available in the literature, Dense Fusion, from the paper DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion, was chosen as the core architecture module.
It is only possible to estimate the pose of a known object under adversarial conditions (e.g. heavy occlusion, poor lighting, …) by combining the information contained in the color and depth image channels. The two sources of information, however, reside in different spaces. The main technical challenge in this domain is to extract and fuse features from heterogeneous data sources. For this reason, Dense Fusion has a heterogeneous architecture that processes color and depth information differently, retaining the native structure of each data source, and a dense pixel-wise fusion network that performs color-depth fusion by exploiting the intrinsic mapping between the data source. Finally, the pose estimation is further refined with a differentiable iterative refinement module.
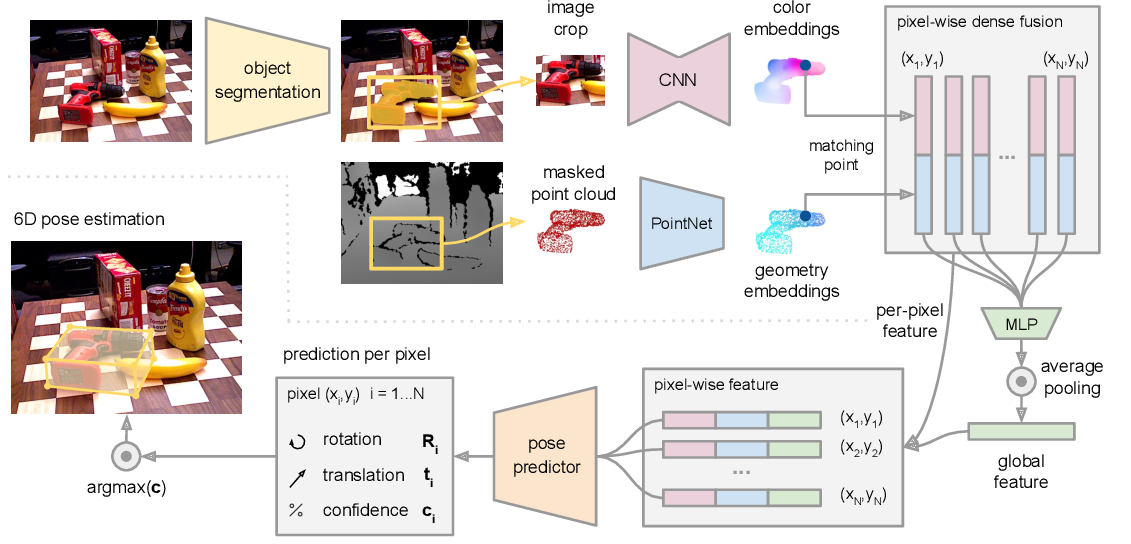
The first stage performs a semantic segmentation for each known object category. For each segmented object, we feed the masked depth pixels converted to a 3D point cloud and the image patch cropped by the bounding box of the mask to the second stage.
The second stage processes the results of the segmentation and estimates the object’s 6D pose. The second stage is composed by different sub-components:
1. Dense Color Embedding Network: CNN-based encoder-decoder architecture that maps an image of size H∗W ∗3 into a H ∗W ∗drgb embedding space.
2. Geometric Embedding Network: variant of PointNet architecture that processes each point in the masked 3D point cloud, converted from segmented depth pixels, to a geometric feature embedding.
3. Pixel-wise Fusion Network: In this module the geometric feature of each point is associated to its corresponding image feature pixel based on a projection onto the image plane using the known camera intrinsic parameters.
4. Pose Estimation Network: it takes as input a set of per-pixel feature and for each of them predicts one 6D pose. The loss to minimize for the prediction per dense-pixel is defined as:
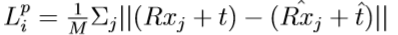
where xj denotes the jth point of the M randomly selected 3D points from the object’s 3D model. p = [R|t] is the ground truth pose where R is the rotation matrix and it is the translation vector, while ˆp = [ ˆR|ˆt] is the predicted pose generated from the fused embeddings of the ith dense-pixel. The above loss function is only well defined for asymmetric objects, for symmetric objects the loss function becomes:
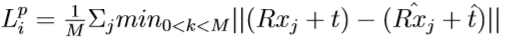
As we would like our network to learn to balance the confidence among the per dense-pixel predictions, we weight the per dense-pixel loss with the dense-pixel confidence, and add a second confidence regularization term:
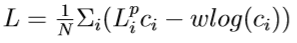
where N is the number of randomly sampled dense-pixel features from the P elements of the segment and w is a balancing hyperparameter. We use the pose estimation that has the highest confidence as final output.
5. Iterative self-refinement methodology: The pose residual estimator network is trained to perform the refinement given the initial pose estimation from the main network
Keeping in mind the objective of this project, that is the 6D pose estimation and tracking of different instances of objects from RGB-D signal, we have identified some points on which to intervene in order to obtain the desired result.
We realized that the first stage of this architecture (the Semantic segmentation module) implied that the presence of only one object for each class of object could be taken into consideration in the same image. It is therefore necessary to revise the object segmentation module in order to enable the management of different instances of the same object in a single frame.
It is also essential to overcome the lack of system for tracking pose objects over time.
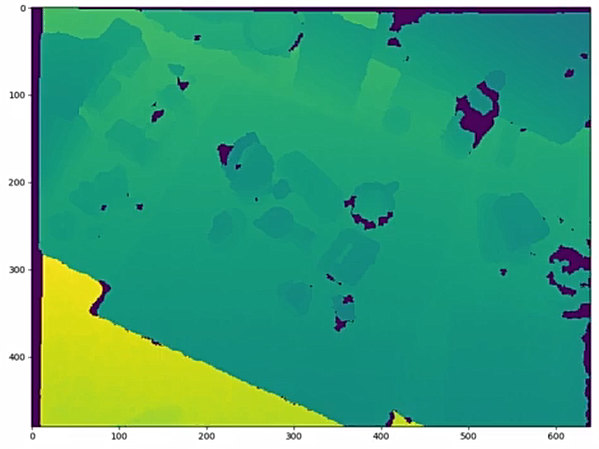
The object segmentation module proposed in the original dense fusion architecture is based on semantic segmentation, this means that the output generated by this module does not allow us to distinguish the different instances of the objects in which we are interested. We are only able to make predictions about the class of belonging of every single pixel, without distinction on the instance of belonging (as can be seen from the image below).

To overcome this problem we have decided to employ a neural network capable of providing instance segmentation of the input. The architecture we have chosen is Mask R-CNN because it is currently the state of the art in the instance segmentation task on different datasets.
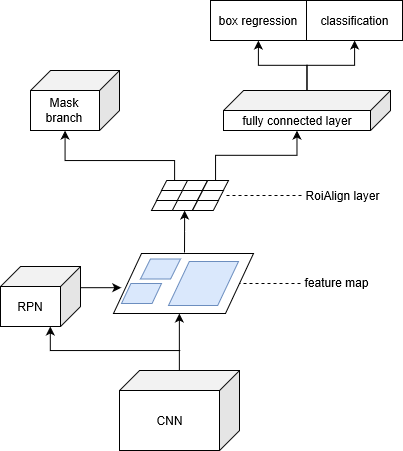
Mask R-CNN (Regional Convolutional Neural Network) is structured in two different stages. First, it generates proposals about the regions where an object could be based on the input image. Second, it predicts the class of the object, refines the bounding box and generates a mask at pixel level of the object based on the first stage proposal. Both stages are connected to the backbone structure: a FPN (Feature Pyramid Networks) style deep neural network.

In order to remedy the lack of system for tracking objects over time, we have decided to integrate a Multiple Object Tracking module. Deep SORT (Simple Online and Realtime Tracking) is a tracking algorithm based on the SORT tracking algorithm and it has been chosen for its remarkable results in the Multiple Object Tracking (MOT) problem. SORT exploits a combination of familiar techniques such as the Kalman Filter and Hungarian algorithm for the tracking components and achieves good performance in terms of tracking precision and accuracy, but it returns also a high number of identity switches.
The main idea of Deep SORT is to use some off-the-shelf model for object detection and then plug the results into the SORT algorithm with deep association metric that matches detected objects across frames.
In Deep SORT predicted states from Kalman filter and the newly detected box in the current frame must be associated, this task is solved using the Hungarian algorithm. Into this assignment problem motion and appearance information are integrated through a combination of two metrics:
1. Motion Information: are obtained using the squared Mahalanobis distance between predicted Kalman states and newly arrived measurements.
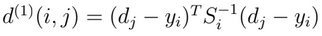
2. Appearance Information: for each bounding box detection dj an appearance descriptor rj is computed. This metric measures the smallest cosine distance between the i-th track and j-th detection in appearance space.
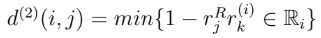
The resulting metric is the following:
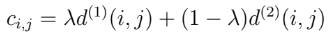
The source of information in this architecture is a RGB-D sensor. At each time instant t our RGB-D camera produces an RGB image and a depth information matrix (related to the distance to the sensor) in a per-pixel basis.
The first step of our architecture is represented by our Mask R-CNN network dedicated to the instance segmentation. At each time instant t an rgb signal is sent to the Mask R-CNN network. Against this signal the network will provide different information: Instance Mask Segmentations, Bounding Boxes and Features Maps. Then the architecture separates off into two distinct branches: one used for pose estimation task and one needed for multiple object tracking.
Pose Estimation branch
The Instance segmentation is used to obtain a crop of the starting image for each object instance identified and a mask of the input depth signal. Then the information concerning color, depth and the classification of the object are propagated to the Dense Fusion network which uses the data supplied as input to estimate the 6DoF of each single object segmented by Mask R-CNN.
Multiple Object Tracking branch
The MOT branch uses the output provided by mask R-CNN in the time instant t and in the previous time instant t − 1. Each bounding box for frame t − 1 is sent to Deep Sort Estimation module. Within this module each detection is represented through a state vector. Its task is to model the states associated with each bounding box as a dynamic system, this is achieved by using the Kalman Filter. Predicted states from Deep Sort Estimation module and detected bounding box from time instant t are associated inside Deep SORT Data Association module. Inside this module motion and appearance information are integrated together in order to obtain a high-performance Multiple Object Tracking.
Our experiments were conducted on the popular LineMOD dataset. The system consists of several interconnected modules, and it is therefore useful to evaluate their performance on the individual tasks.
Pose Estimation results
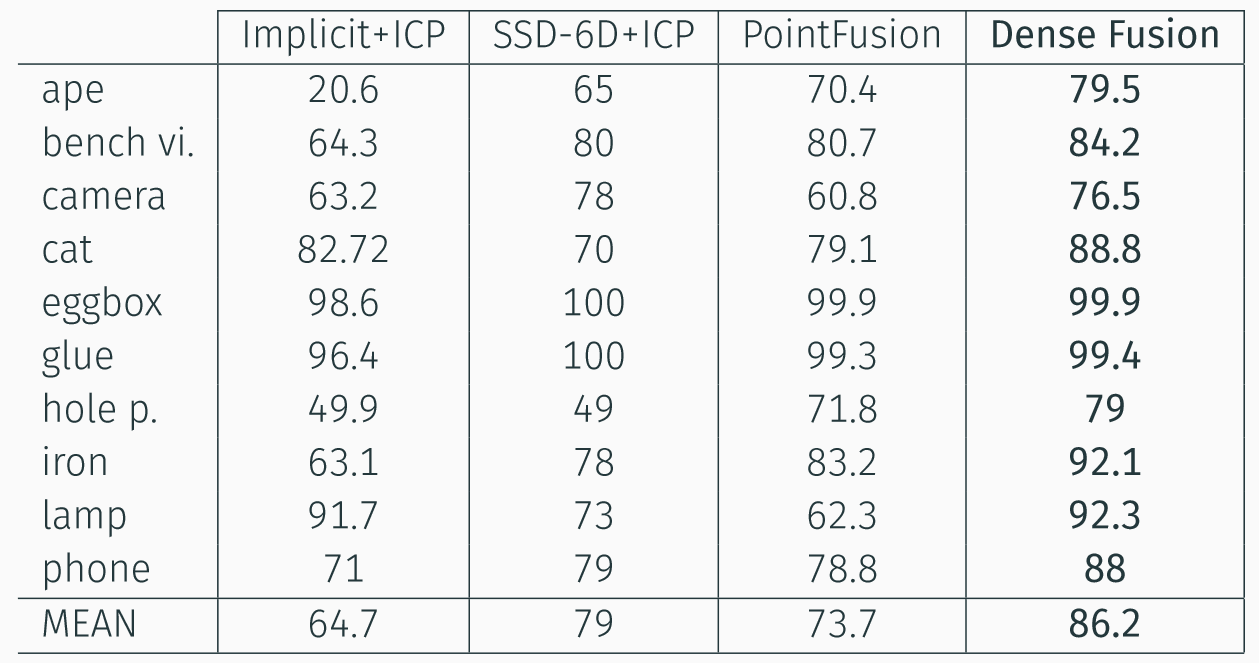
In order to evaluate 6Dof pose estimation results we computed the average distance of all model points from their transformed versions. We say that the model was correctly detected and the pose correctly estimated if km*d ≥ m where km is a chosen coefficient (0.1 in our case ) and d is the diameter of M. The results on LineMOD are shown in the table below together with results of other popular methods.


Instance Segmentation results
In order to evaluate the results obtained on our test set, we decided to use the mAP (Mean Average Precision) a commonly employed metric used for evaluating object detectors. The mAP corresponds to the average of average precision of all classes.


MOT results
We chose two different metrics to evaluate performance in the MOT task:
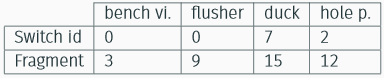
The results for some selected objects are shown in the table below.
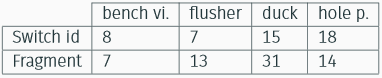
We realized that the sampling frequency of the images in the sequence is quite low, moreover the camera moves around the objects. Given these premises we can understand why we obtained these rather low performances.
Since it is possible to change the metric used for the data association, we chose to change the weight given to the appearance information extracted from the feature maps provided by Mask R-CNN. The results obtained increasing the weight of appearance information with respect to motion information is shown in the following table.

We have designed and implemented an architecture that uses RGB-D data in order to estimate the 6DoF pose of different object instances and tracking them over time.
This architecture is mainly based on Dense Fusion.
The segmentation module has been replaced with a custom version of Mask R-CNN. It has been modified in order to extract feature maps computed by the RoiAlign layer.
Finally, Deep SORT was added to the architecture in order to implement our Multiple Object Tracking module.
Regarding the possible future developments of this work, there are several paths that could be investigated:
I hope you enjoyed reading this article!
Written by Lorenzo Graziano - Agile Lab Data Engineer
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!
Using pySpark with Google Colab & Spark 3.0 preview - Meetup in Milan, 11th December 2019
Going Deep into Real-Time Human Action Recognition
Don't miss our next meetup, we will talk about Deep Generative Models for Computer Vision - 11 June 2020