Apache Spark is the most widely used in-memory parallel distributed processing framework in the field of Big Data advanced analytics. The main reasons for its success are the simplicity of use of its API and the rich set of features ranging from those for querying the data lake using SQL to the distributed training of complex Machine Learning models through the use the most popular algorithms.
Given this simplicity of using its API, however, one of the most frequently problem encountered by developers, similar to what happens with most distributed systems, is the creation of a development environment where you can test your applications by simulating the execution of code on multiple nodes of a cluster.
Although Spark provides a local execution mode, it may hide a number of issues due to the distributed mechanism of code execution, making testing ineffective. That’s why the most effective way to create a test environment that is more like a production cluster environment is to use Docker containers.
An additional benefit of using this approach is that you can test your applications on different versions of the framework by simply changing a few parameters in the configuration file.
In our example we will use version 3.0, the test cluster hypothetically could be useful in testing the compatibility of our applications with the recently released major version as well as to test the new features introduced.
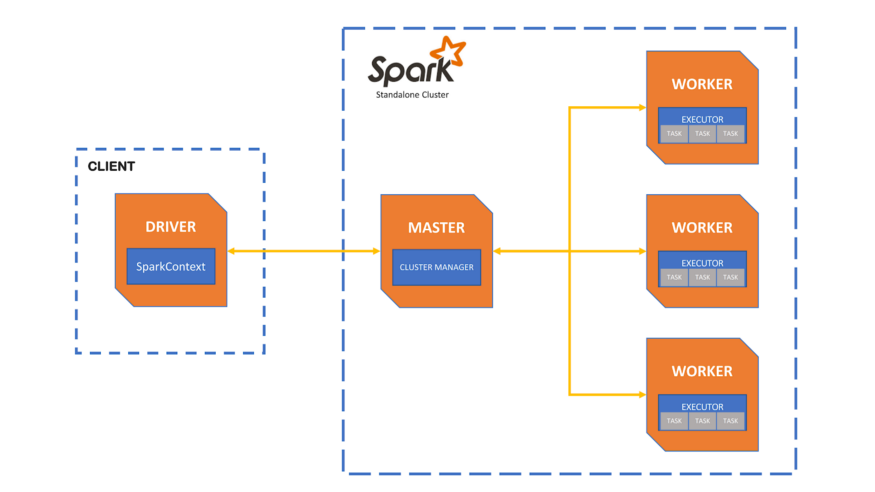
Spark is designed so that you can run on different types of clusters. This is done by supporting several cluster managers such as YARN, the Hadoop platform resource manager, Mesos or Kubernetes. If an existing cluster infrastructure is not available, Spark can run on an integrated resource manager/scheduler. This is commonly referred as “standalone” cluster mode.
In our example, we’ll create a cluster consisting of a master node and 3 worker nodes like the one in the image below.
To setup our cluster, we will use the images created by the developers of the open source project “Big Data Europe”, whose sources are available on GitHub: https://github.com/big-data-europe/docker-spark.
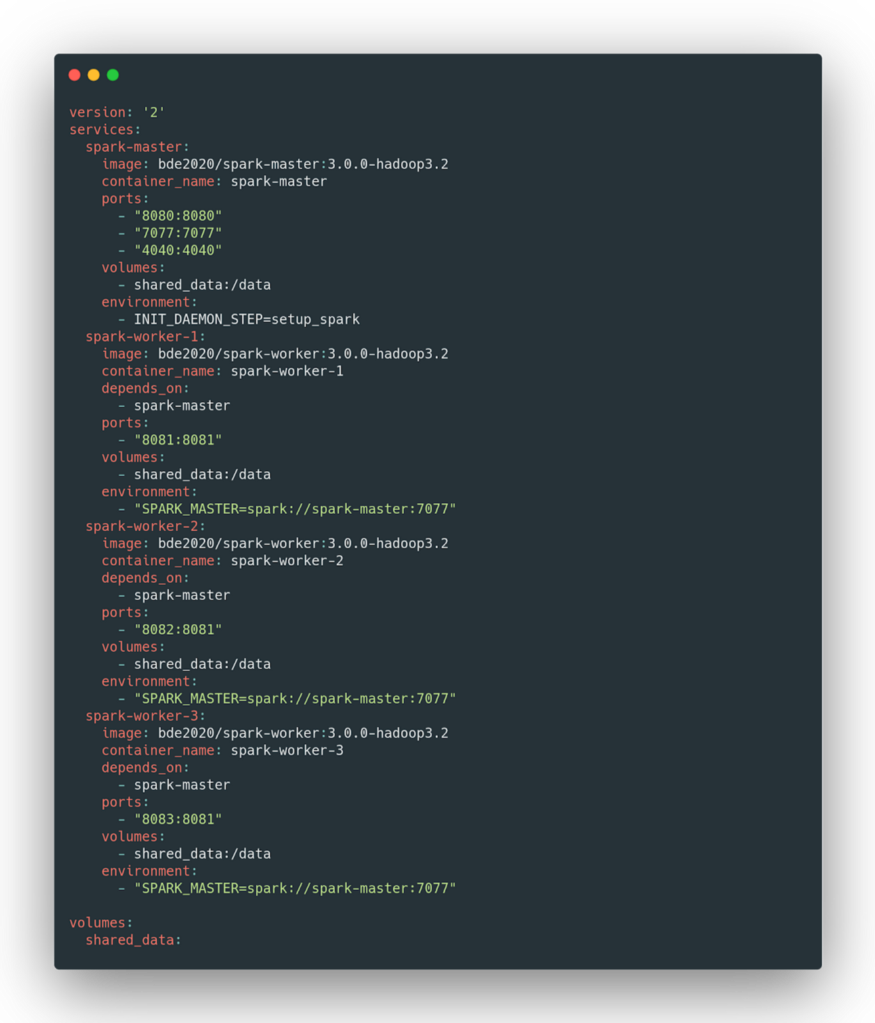
We’ll make small changes to the docker-compose.yml configuration file to size the number of nodes and most importantly to add a persistent volume for reading/writing data during our experiments.
This is the configuration file that we’re going to use.
You can then start the cluster and run a shell on the master node once it starts.
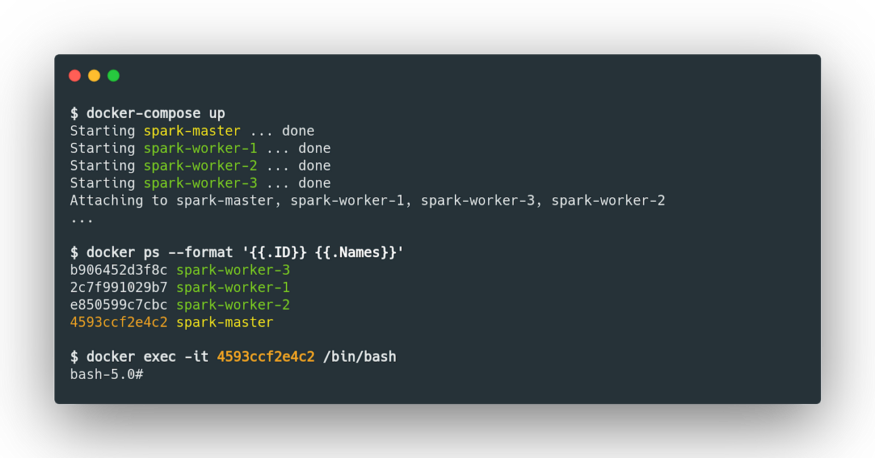
And finally launch our spark-shell.
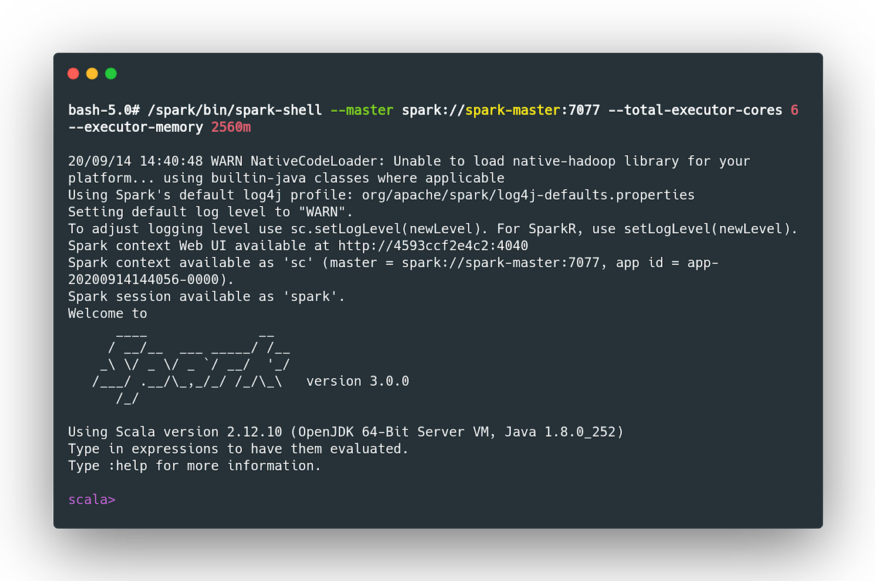
At the time of testing, I am using a laptop with a CPU with 8 cores and 16Gb of RAM. That’s why I allocated 2 cores for each executor (6 in total) and 2.5 Gb of RAM.
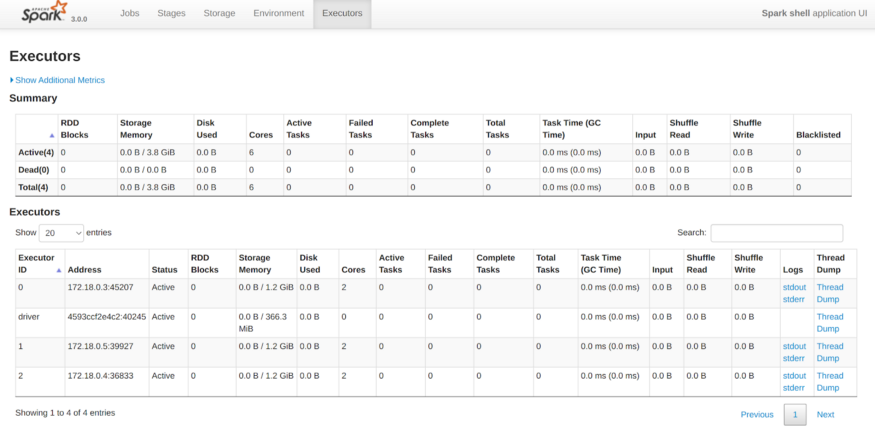
Our development cluster is ready, have fun!
Written by Mario Cartia - Agile Lab Big Data Specialist/Agile Skill Managing Director
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!