TECH ARTICLE
A Data Lake new era
A new wave is coming in the field of Big Data technologies: real-time Data-Lakes and low-cost DWHs.
Data Quality for Big Data
In today’s data intensive society Big Data applications are becoming more and more common. Their success stems from the ability to analyze huge collections of data opening up new business prospectives. Devising a novel, clever and non trivial use case for a given collection of data is not enough to guarantee the success of a new enterprise. Data is the main actor in a big data application: therefore it’s of paramount importance that the right data is available and the quality of such data must meet certain requirements.
In such scenario we started the development of DataQuality for Big Data, a new open source project that automatically and efficiently monitors the quality of the data in a big data environment.
One of the main targets of a big data application is to extract valuable business knowledge from the input data. Such process does not involve a trivial computation of summary statistics from the raw data. Furthermore traditional tools and techniques cannot be applied efficiently to the huge collections of data that are becoming commonplace. To achieve the indented objective a common approach is to build a Data Pipeline that transforms the input data through multiple steps in order to calculate business KPIs, build/apply machine learning models or make the data usable by other applications.
Data Pipeline workflow example
In this scenario there it’s quite common to have pre-defined input data specifications and output data requirements. Then the pipeline steps are defined, relying on the such specifications to achieve the desired output.
However in most cases we do not have full control over the input data or we may have specifications and assumptions that are based on past data analysis. Unfortunately (and fortunately at the same time) data changes over time and we would be able to keep track of such changes that could violate our application assumptions. In some other cases data can be corrupted (there are a lot of moving parts in complex environments) and we don’t want dirty data to lead to unusable results. We’d like, instead, to intercept and prevent this situation, restore the input data and run our data pipeline in a clean scenario.
Another problem is related to the data pipeline itself. After development tests and even massive UATs there could always be some kind of bug, due to wrong programming, unforeseen corner cases in the input data or to a poorly executed testing/UAT phase. Constantly checking our core application properties through the time could be a good way to catch this bugs as soon as possible, even when the application is already in production.
A continuous Data Quality check on input, intermediate and output data is therefore strongly adivisable.
Manual checking of some properties and constraints of the data is of course possible but not affordable in the long run: an automatic approach is needed.
A possible solution could be to implement project specific controls and check of the data. This has the obvious advantage to integrate quality checks in different parts of the application. There are however several drawbacks:
A better solution is be to have a generic Data Quality Framework, able to read many data sources, easily configurable and flexible to accomodate different needs. That’s where our framework shines!
DQ is an open-source framework to build parallel and distributed quality checks on big data environments. It can be used to analyze structured or unstructured data, calculating metrics (numerical indicators on data) and performing checks on such metrics to assure the quality of data. It relies entirely on Spark to perform distributed computation.
Compared to typical data quality products, this framework performs quality checks at the raw level. It doesn’t leverage any kind of SQL-like abstraction by using Hive or Impala because they perform type checks at runtime hiding bad formatted data. Hadoop has structured data representation (e.g. through Hive) but mainly it stores unstructured data ( files ), so we think that quality checks must be performed at raw level without typed abstractions.
With DQ is possible to:
DQ engine is even more valuable if inserted in an architecture like the one shown below:
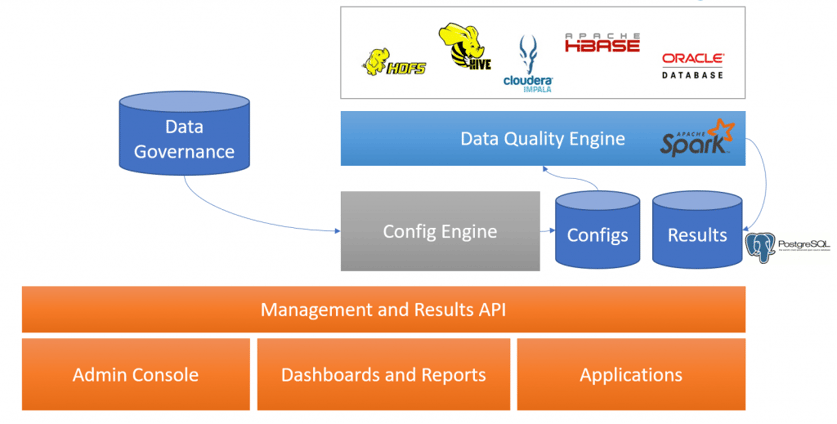
 Data Quality solution overview
Data Quality solution overview
In this kind of architecture our Data Quality engine takes some configuration as input where it finds what data has to be checked, then it fetches it, calculates the metrics and performs the configured checks on them. The results are then saved in a data storage, in the example MongoDB. In this scenario a configuration engine (the green box) could be very helpful to configure sources/metrics/checks with a simple web application or automatically create standard checks for every input listed in a Data Governance of an enterprise. Other components can be implemented on top of this architecture to send reports, build graphic dashboard or apply some recovery strategies in case of corrupted data.
To understand what is the state of the art of the project we first have to better specify what are the main abstractions of the engine:
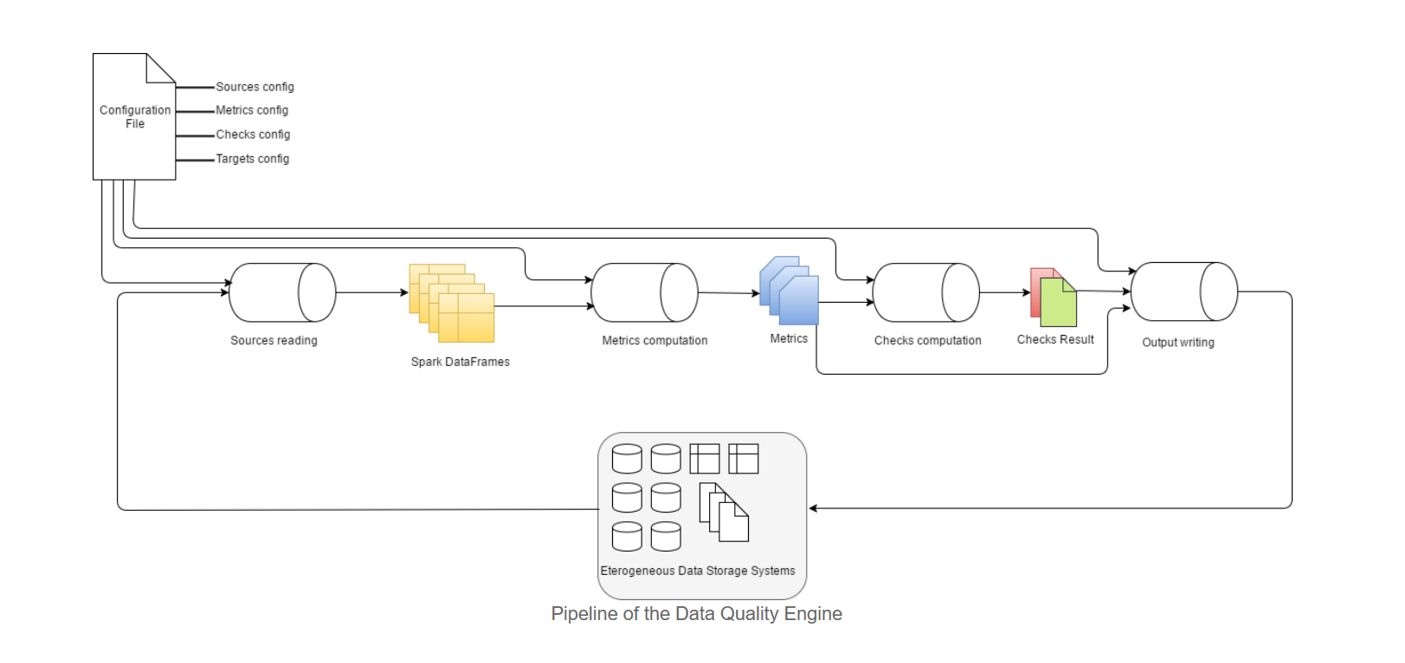
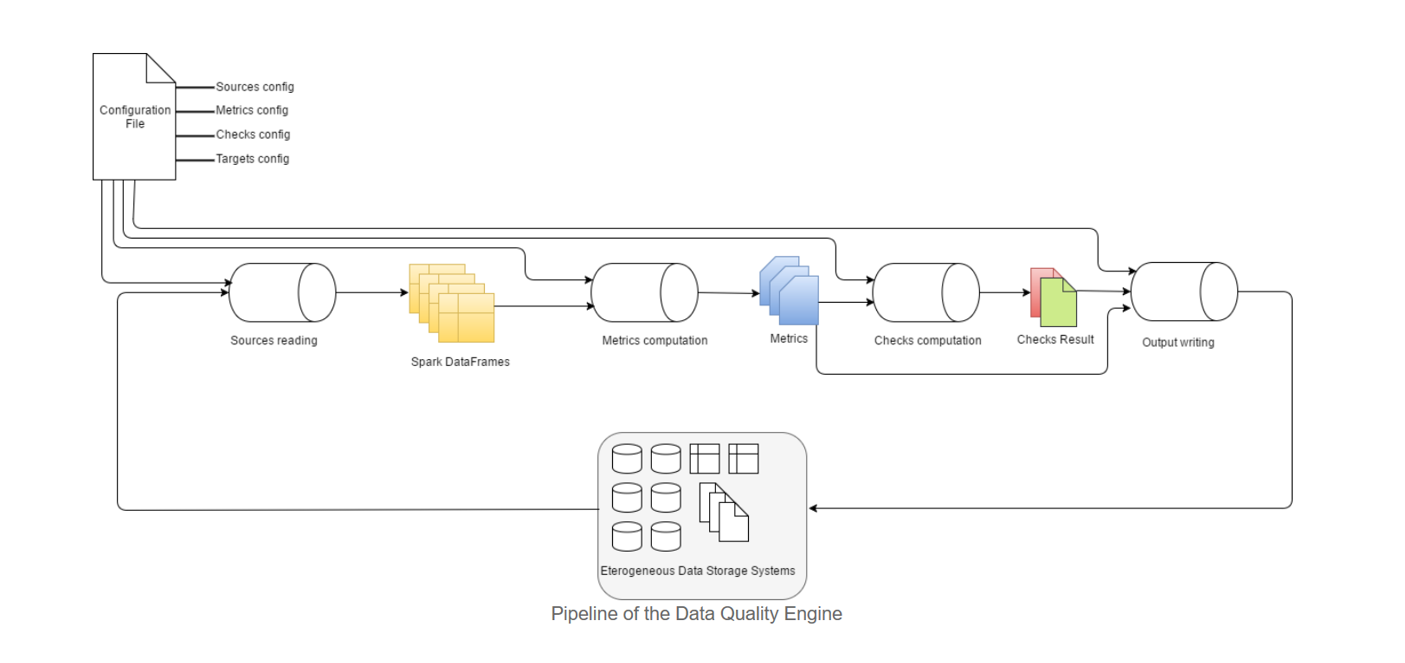
In the schema below is described the high level pipeline of the DataQuality engine.
Below a quick recap of what is already available. As already said any other component can be plugged in.
Now we look to a possible scenario to understand a possible usage of DataQuality and its configuration pattern.
Suppose that we are in a bank IT department and our application uses as input data a daily transaction flow that arrives in CSV format on HDFS. The expected structure of the file is the following
On a daily basis we want to check the quality of the received data. Some required high level properties could be:
Let’s see how we can transform these requirements in terms of source, metrics and checks configuration for the DataQuality framework.
Here you can find a possible configuration file for the above use case
DataQuality Configuration example
In order to read the input file the only thing we have to do is to add a source in our sources list specifying an id, the type of the source, the HDFS path, the format of the file (CSV, fixed length, … ) and other few parameters. The file date in the path definition will be automatically placed in the specified format by the framework depending on the run parameters.
Then we have to formalize our high level requirements in terms of metrics and checks
In the configuration file metrics and checks are defined separately because metrics are independent w.r.t. checks in which they are used. In fact a metric can be re-used in different checks (e.g. metric A)
In the bottom list there are the output files configuration.
Instructions on how to run the framework injecting a custom configuration file are in the GitHub project page
It should be clear that assuring data quality over time is a must in a big data environment. Achieving such goal with automatic approach is needed and it is not affordable or feasible to build ad-hoc solutions in complex big data environments for every project/data source.
An open, flexible, extensible framework such as DataQuality is the solution that guarantees a high level of control over quality of data in different contexts and scenarios, requiring only minor configuration to extend its usage.
The pluggable nature of the project make it highly reusable and open to continuous extensions. It’s also open-source, so you are welcome to contribute to the project and make it even better!
GitHub https://github.com/agile-lab-dev/DataQuality
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!
A new wave is coming in the field of Big Data technologies: real-time Data-Lakes and low-cost DWHs.
Does your city collect open data? How would you use this data to improve public services?
NewSQL….the new era of Relational Databases?