The race to become a data-driven company is increasingly heated, challenging the data engineering practice foundations.
Let’s look at the Data Mesh phenomenon, which proposes a socio-technical approach to decentralize the data ownership to the business domains.
The “quick buy-in” that Data Mesh principles obtain from business executives demonstrates that they hit a real pain point for big enterprises. Greater agility and a better time to market in data initiatives are strongly needed.
To successfully implement a Data Mesh on a large scale, a non-trivial shift across several pillars is needed:
- Organization
- Data culture / Data literacy
- DataOps and DevOps
- Data Engineering practices
- Delivery processes
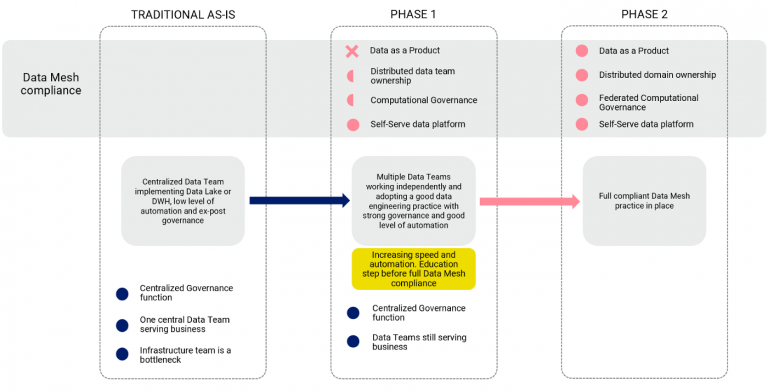
For this reason, it is advisable to proceed step by step and make a series of improvements to the technical and process-oriented pillars mentioned above before jumping into the Data Mesh adoption journey. This way, everything will come more naturally, and it will be possible to focus more energy on the elements opposing the most significant resistance: people and organization.
For example, the Data Engineering practice part typically falls under the responsibility of a single department and does not require multi-functional convergence to make the change happen.
On the other hand, overall delivery processes are usually more cross-functional and, without an organizational shift, are difficult to evolve.
In the data engineering practice, we can move several steps towards the following goals to boost data mesh adoption:
- increase the speed of delivery
- enable multiple and parallel teams to work on different initiatives in a more autonomous and independent way
- increase practice standardization
- automate the data governance function and make it computational
Generally speaking, there are four ways to set up a data engineering practice, and they depend on the size and the maturity of the data ecosystem in the company. The latter is the one we think could be an excellent first step toward the data mesh adoption:
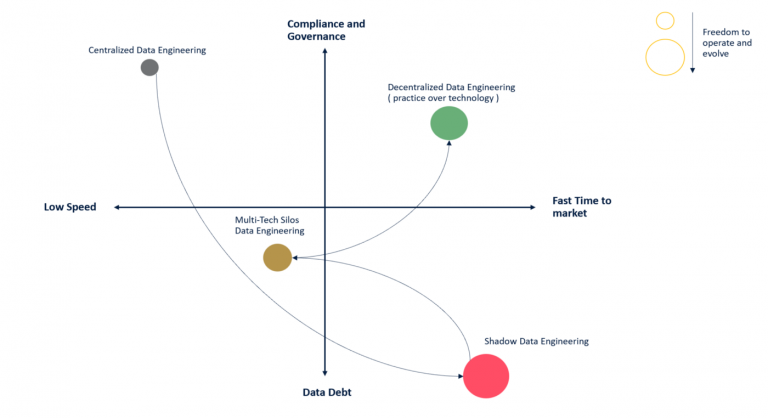
Centralized Data Engineering
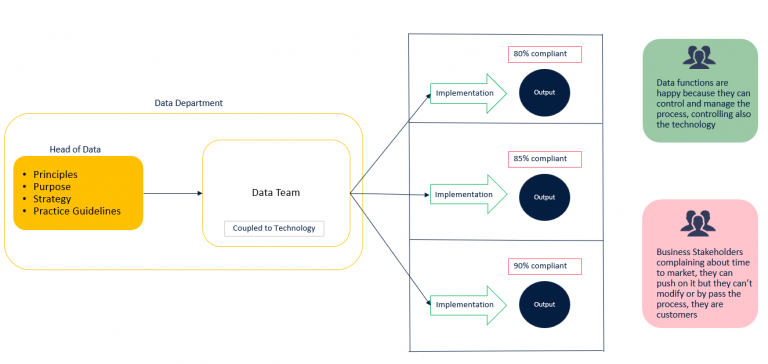
The centralized approach is the most common when a company jumps into the world of data. Hiring a Head of Data ( “been there done that” ) is the first step. She will begin to structure processes and choose a technology to create the data platform. The platform contains all the business data, which are organized and processed according to all the well-known requirements we have in data management.
In this scenario, data processing for analytical purposes occurs within a single technology platform governed by a single team, divided into different functions ( ingestion, modeling, governance, etc.). Adopting a single technology platform generates a well-integrated ecosystem of functionalities and an optimal user experience. The platform typically also includes most of the compliance and governance requirements.
The Data Team manages the platform as well as the implementation of use cases. For those defining principles and practices, it is straightforward to align the team because they have direct control over the people and the delivery process. This methodology ensures a high level ( at least in theory) of compliance and governance. However, it doesn’t typically meet the time-to-market requirements of business stakeholders because the entire practice turns out to be a bottleneck when adopted in a large-scale organization. Business stakeholders ( typically those paying for data initiatives ) have no alternatives but adapting to the data team’s timing and delivery paradigm.
Centralized Data Engineering
Shadow Data Engineering
When “Centralized Data Engineering” generates too much frustration for business users, we typically see the so-called “Shadow-IT” emerging, thus leading to:
- Adoption of new technology platforms for data processing and manipulation
- Creation of new teams (often composed of data scientists) delivering data initiatives directly into production to achieve better time-to-market
- Creation of “bubbles” operating outside the expected standards
This practice, at first, is seen purely as an added value because, suddenly, business initiatives go live in unbelievable times, and it also creates the illusion that “in the end, it is not that difficult to deal with data.”
This generates a flywheel effect: budgets increase, the company starts to leverage the pattern more and more, and new technologies are introduced.
Since all these technologies don’t usually natively integrate with each other, it immediately becomes a data integration problem because all these platforms and teams need to insource data to operate.
As soon as data is stored, it requires dealing with all the issues related to Data Management ( security, privacy, compliance, etc. ). Business Intelligence is typically the first area where this pattern will happen because the business operates autonomously with dedicated teams. BI tools, instead of just allowing to explore and present data, often turn into full-fledged data management tools because they require ingesting a copy of the data ( data integration ) to achieve better performance.
The same phenomenon occurs with Machine Learning platforms, allowing data scientists to analyze, generate and distribute new data within an organization, operating with high flexibility and freedom. Machine learning platforms rapidly become a new way to deliver data to the business.
At the beginning all these patterns seem to generate value for the company. Still, whenever we institute practices and technologies disconnected from data governance and compliance needs, we generate Data Debt. This debt manifests itself late and on a large scale with the following effects:
- Inconsistent and unreliable data
- High maintenance costs
- Data issue troubleshooting becomes hard
- Hard to keep people accountable for the generated data.
When Shadow Data Engineering appears, the core data team loses credibility because the organization will only see lightning results and related business impacts. It is tough to demonstrate the negative effects in the long term when these are not visible yet.
After a few years, it will be highly complicated to make a comeback when collateral damages begin to appear.
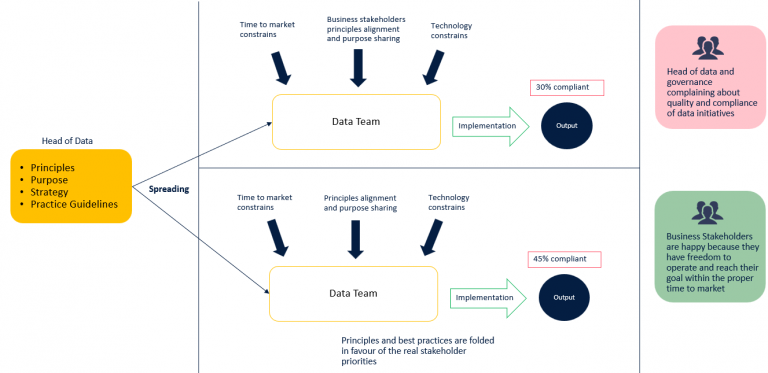
Establishing good data engineering practices in this scenario is impossible, even with a clear mandate. When a Head of Data asks to implement some data management best practices, stakeholders operating in shadow mode formally embrace them. Anyway, being fully autonomous on their platform, their personal goals will always bypass the guideline implementation. Stakeholder’s MBOs always target short-term results, and teams working on data receive pressure to deliver business value.
Shadow Data Engineering
Multi-Tech Silos Data Engineering
By the time Shadow Data Engineering runs for a couple of years, it is no longer possible to return to Centralized Data Engineering. Technologies have penetrated the processes, culture, and users, who become fond of the features rather than their impact.
Centralizing again on a single platform would cost so much and slow down the business. As it is true that the limits of the shadow approach are now clear, the business benefits in terms of agility and speed have been valuable, and none is willing to lose them.
Usually, companies tend to safeguard the technologies that have expanded the most, adding a layer of management and governance on top, creating skill and process hubs for each. Typically, they try to build ex-post an integration layer between the various platforms to centralize data cataloging or cross-cutting practices such as data quality and reconciliation. This process is complicated because the platforms /technologies have not been selected with interoperability in mind.
The various practices will be customized for each specific technology, ending up with a low level of automation.
Anyway, it will be possible to reduce the data debt. Still, the construction of these governance and human-centric processes will inevitably lead to an overall slowdown and effort increase without any direct impact on the business.
Although it will be possible to monitor and track the movement of data from one silo to another, as followed by audit and lineage processes, the information isolation of the various siloes will persist.
Decentralized Data Engineering
Decentralization of data engineering comes through deep standardization, which must be independent of the underlying technology ( practice over technology ). Technology selection will happen with clear drivers as soon as we prioritize the practice.
Adapting technology to practice often means depowering the technology and building custom components, using only some features and not others.
There is a massive difference between adapting a practice to a set of technologies and related features and adapting and selecting technologies to fit into a practice.
A clear set of principles must be a foundation when defining a practice.
In decentralized data engineering, we want to enable many independent data teams to achieve a good time to market and velocity without generating data debt and reaching high levels of governance. Here is a set of principles that are the foundation of this approach:
Zero effort best practices
Transforming document-oriented guidelines into code is extremely hard and generates a non-negligible amount of effort. As other priorities jump onto the data team, it will perceive policy adherence as less essential and drop them when critical business-side time-to-market issues arise.
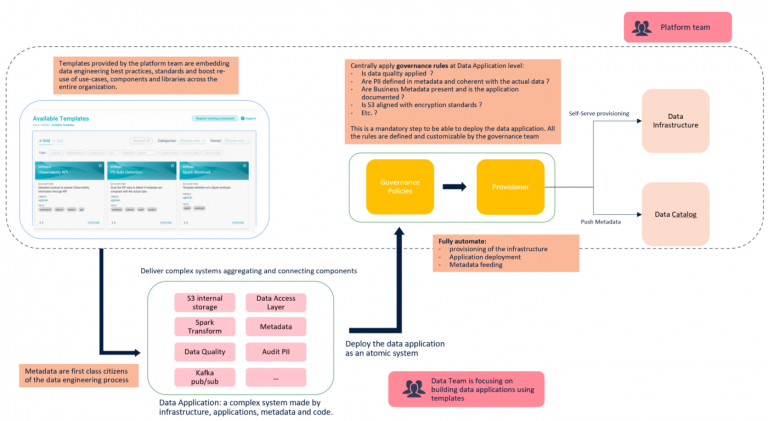
Best practices should bring added value without creating a burden. Putting the developer experience at the center is necessary, making the adoption straightforward. They should directly impact speed and quality instead of becoming an obstacle. An excellent way to adopt best practices is by providing templates/scaffolds. Templates are far better than frameworks because they are not creating bottlenecks in the delivery process and don’t represent an obstacle to the agility and evolution of each data initiative.
Templates have the following purposes:
- Facilitating the setup of a project and the use of a specific technology by providing a quick win
- Embedding and standardizing best practices and patterns saving data teams’ time and effort due to the built-in adoption
- Including side effects or default behaviours within all applications to allow their standardization( data lineage inference, encryption, etc.) regardless of technology
- Increasing the reuse of software assets and use cases across multiple teams without having to build frameworks that, in the long run, prove themselves to be an operational bottleneck and an obstacle for the innovation
- Speeding up the time to market to go from the conception of a use case to its implementation in the shortest possible time, focusing mainly on business logic.
Templates should collect “lesson-learned” from the data teams and should be developed and maintained by leveraging a feedback loop between the platform team and the data team, not to create a silo effect between the enablers ( the platform team ) and the doers ( data team ).
The data team should be able to contribute templates to the platform team; these contributions will help consolidate the data practice developed within the data team and make it available to other teams.
Templates focus on time to market. This is crucial to developing a successful use case and will help data teams deliver business value as fast as possible.
To be able to evolve use cases organically, templates should offer a low-effort upgrade path for instances of those templates by leveraging:
- Automated code rewrites: data team should not care about upgrades; they are done for them.
- Compatibility test kits: validating if the use case is compliant with shared platform services before and after the upgrade
- Extensive release notes: the data team can easily understand why it should care about upgrades and which benefits and risks this upgrade bring
Internal Data Engineer ( Developer ) Platform
It is a layer on top of technology that enables automation and standardization of configuration management, deployment, infrastructure orchestration and RBAC processes. The platform team provides a range of facilities ( including templates) to the data teams:
- increasing their productivity and happiness
- reducing boilerplate
- increasing their level of ownership and engagement, as they can move from ideation to production without involving other teams, but following a standard process.
Platform thinking is crucial to decentralization, but we are not discussing a technology platform. Here we are focusing on a practice platform that can help creating a common workflow on top of multiple technologies and across numerous teams, sharing facilities and experiences about value creation.
Policy as code
The founding elements of the practice must be codified and visible to all the teams. Policy application should be fully automated, independent of the underlying technology, part of the overall delivery process and deeply integrated with Internal Data Engineer Platform.
Policies can be applied to compliance, security, information completeness, data quality, governance, and many other relevant aspects of data management, creating a heterogeneous but trustable ecosystem.
When we talk about “as code,” it means being part of the software development lifecycle.
Technology independence
We need to be able to apply the practice to all the technologies being part of the company’s landscape. In addition, introducing new technologies and tools must always be possible without impacting the ecosystem. Introducing tech X should not impact tech Y. We must focus on decoupling and pattern generalization because technologies come and go while practices evolve.
When introducing a new technology, the first driver to value is interoperability ( at the data, system and process level).
Each data team needs to be able to choose the option they prefer within a basket of technologies with a high level of interoperability enabled by the platform team.
It is crucial to select composable services and open formats/protocols.
Please pay attention to decoupling storage and computing because it allows better technology interoperability and cost distribution among producers and consumers.
Data Governance democratization and automation
To remove central process bottlenecks, the governance activities ( data modelling, metadata, data classification, etc. ) should become part of the development cycle and the “definition of done” for all the data teams. It is essential to make it simple and intuitive; that’s why the Internal Data Engineering platform and policy as code play a crucial role in embracing this principle.
Data governance should move into the development lifecycle to generate metadata before that data goes into production and to be in the position to apply quality gates to them.
It means distribute some duties to the data team instead of relying on central governance team activities that will focus more on creating the process and the automation rather than explicitly policing and gate keeping.
DevOps/DataOps First
It is crucial to embrace high levels of automation throughout the process to enable teams to be independent while still being in control of the delivery quality. An internal data engineering platform without full automation does not create enough value to reach wide adoption. Automating infrastructure and resource provisioning is crucial to provide good agility and speed benefits to the teams.
DevOps also is essential to create the proper development process and automation culture, also including the placement of quality gates before the data goes into production.
- Reproducible local environments: Following a DevOps practice the platform infrastructure needed for local development should be reproducible on a developer laptop in order to speed up development and diagnosis of problems
- Reproducible data scenarios: A developer should be able to bootstrap a local development environment or a remote development environment automatically sampling data needed to reproduce an expected scenario
Data Contract First
In a decentralized practice is not possible anymore to orchestrate all the data pipelines and organize the delivery of multiple teams because no one is owning such accountability. We need clear contracts between data producers and consumers.
Data Contract first means that the contract definition is happening during the development lifecycle. Then it automates the creation of resources and standardizes the metadata exchange mechanisms.
The orchestration is no longer a centralized process but a reactive, modular and event-driven ecosystem of schedulers.
Policy as code principle can help to enforce, control and improve data contracts because they are mainly declarative.
Also, data contracts must be highly standardized and regulated by policies, for example:
- No breaking changes as long as a data contract has a consumer.
- At least six months of deprecation period in case of dismission
- A physical endpoint is part of the contract
Data follow data contracts, but often data contracts evolve over time, in case there are no breaking changes, data should be automatically upgradable to new schema definition by hooking in platform lifecycle events via code or by standard “procedures”
A service to discover and resolve data contracts is highly recommended.
Declarative Data Transformations
This is a direct consequence of a Data Contract first approach. With data contracts, we want to shift the focus to the result that we want to achieve. But data is always the result of a transformation that should be strongly connected with the data contract. The only way to do it is by adopting a declarative semantic integrated with the data contract. Otherwise, you could have pipelines generating information not aligned with the declared data contract. Connecting Data Contracts and transformations guarantees the consistency of schema metadata and lineage information out of the box. There is no time to keep a layer of documentation aligned when we have multiple teams working with high agility and speed. Documentation should be generated directly from the artifacts and related inferred metadata.
Wrapping Up
So in the decentralized data engineering practice, the platform team must build and maintain an Internal Data Engineering Platform where it should publish a set of pre-built templates ( scaffolds ) and create policies ( as code ) to enforce the process.
This platform must also put the deployment process on guardrails through DevOps/DataOps methodologies, enforcing policies and quality gates and abstracting the process from specific technologies.
The Platform team facilitates the job of the data teams by introducing and adopting new technologies in the platform thus giving them the opportunity to innovate and feel accountable end-to-end.
At Agile Lab, we had the opportunity to realize how this methodology could offer an excellent time to market and significant autonomy for data teams without introducing data debt and keeping it under control because of high standardization and regardless of the technology.
I realize that building the Internal Data Engineering Platform requires costs and effort, but they should be supported by a long-term strategical vision. Furthermore, there are no free lunches in the data world.
Decentralized Data Engineering
Decentralized data engineering practice aligns with the Data Mesh paradigm but does not cover organizational aspects and does not embrace data domain-driven ownership and federated governance. It is just focusing on data practice decentralization, automation and interoperability. This pattern could be considered a first step towards the Data Mesh adoption, and the good thing is that this one could be driven entirely by the IT/Data department without involving business domains and obtaining the following improvements:
- Interoperability: is a critical element of embracing and adopting the concept of Data as a Product.
- Policy as code: contributes to adopting the principle of “Federated Computational Governance,” providing a way to shift from guidelines to enforce governance rules at the code level automatically.
- Internal Data Engineering Platform: it boosts the platform thinking that is crucial when embracing the “Self Serve data platform” principle and a step towards the Data Utility Plane and the Data Product Developer experience plane implementation.
Thanks to Roberto Coluccio.