Going Deep into Real-Time Human Action Recognition
A journey to discover the potential of state-of-the-art techniques
Hi all! My name is Eugenio Liso, Big Data Engineer @ Agile Lab, a remote-first R&D company located in Italy. Our main focus is to build Big Data and AI systems, in a very challenging — yet awesome — environment.
Thanks to Agile Lab, I attended a 2nd level Master’s Degree in Artificial Intelligence at the University of Turin. The Master’s thesis will be the main topic of this post. Enjoy ?
Human Action Recognition: What does it mean?
Imagine that a patient is undergoing a rehabilitation exercise at home, and his/her robot assistant is capable of recognizing the patient’s actions, analyzing the correctness of the exercise, and preventing the patient from further injuries.
Such an intelligent machine would be greatly beneficial as it saves the trips to visit the therapist, reduces the medical cost, and makes remote exercise into reality¹.
With the term Human Action Recognition, we refer to the ability of such a system to temporally recognize a particular human action in a small video clip, without waiting for it to finish. This is different from Action Detection, since we do not locate where the action is spatially taking place.
Specifically, my task is to predict in real-time one out of three possible human actions: falling, running or walking.
The most careful readers will already have noticed the “movement-wise” difference between these three actions. Although the falling action has, potentially, very different “features” from the other two, and is therefore a good candidate to be one of the easiest to predict, the same cannot be said between walking or running. Indeed, these two actions share some common characteristics.
Since building ad hoc features for this kind of task can be expensive and complicated, a powerful tool comes to rescue me: Deep Neural Networks (DNN).
In the following sections, I will provide some details about the DNN’s I used to accomplish the task and, finally, we will discuss the results of my experiments.
3D-ResNeXt vs Two Stream Inflated 3D ConvNet (I3D)
After a careful and detailed research of the state-of-the-art, I have decided to focus on two — architecturally different but very promising — DNN: the 3D-ResNeXt and the Two Stream Inflated 3D ConvNet.
Luckily, the authors already provide the two networks pre-trained on Kinetics, a VERY huge dataset that has been proven to be an excellent starting point when training from-scratch a newly-built network for the Human Action Recognition’s task.
3D-ResNeXt
The first one is called 3D-ResNeXt, a Convolutional-based network (CNN) implemented in Pytorch. It is also based on ResNet, a kind of network that introduces shortcut connections that bypass a signal from one layer to the next one. For more details, refer to the author’s paper².
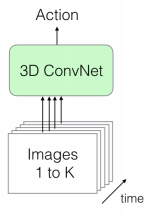
This kind of network takes K 112x112 RGB frames as input, while its output is the predicted action. Regarding this, I have set K = 16 for two reasons:
- Taking 16 frames as input is a reasonable default, since almost all architectures have that kind of time granularity
- Almost all the videos used during the training phase are recorded at 30 FPS. Although the running or walking actions seem not to be highly impacted (since they can be roughly considered “cyclical”), I have empirically established that, by increasing the input frames, the falling action becomes “meaningless”, since 16 frames satisfactorily enclose its abruptness. It might also be a good idea to set K = 32 if the input videos were recorded at 60 FPS.
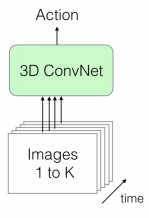
An overview on how 3D-ResNeXt (and more generally, the 3D-ConvNets) receives its inputs.
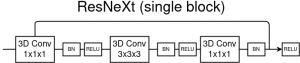
The main building block of the 3D-ResNeXt network. The ResNeXt block is simply built from a concatenation of 3D-Convolutions.
Two Stream Inflated 3D ConvNet (I3D)
The other network is called Two Stream Inflated 3D ConvNet — from now on we will call it I3D for the sake of brevity. It is implemented by DeepMind in Sonnet, a library built on top of Tensorflow. For more details, please refer to the author’s paper³.
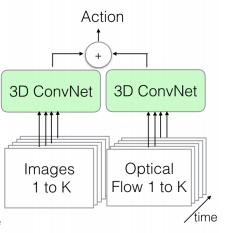
The I3D, differently from the 3D-ResNeXt, uses two kinds of inputs:
- K RGB frames, like the 3D-ResNeXt, but their size is 224x224
- K Optical Flow frames with size 224x224. The Optical Flow describes the motion between two consecutive frames caused by the movement of an object or camera

Fine-Tuning with Online Augmentation
Before stepping into the juicy details about the employed datasets and the final results — don’t be in a hurry! — I would like to focus on the Augmentation, a fundamental technique used when training a CNN. Speaking broadly, during the training phase (on every mini-batch), we do not give the exact same input to the CNN (in my case, a series of frames), but a slightly modified version of it. This increases the CNN’s capability to generalize better on unseen data and decreases the risk of overfitting.
Of course, one could take a dataset, create modified frames from the original ones and save them to disk for later use. Instead, I use this technique during the training phase, without materializing any data. In this case, we talk about Online Augmentation.
The “units” or “modules” responsible of producing a frame similar to the original one are called filters: they can be compared to a function that takes an input image i and produces an output image i’. For this task, I have chosen 7 different filters:
- Add and Multiply: add or multiply a random value on every pixel’s intensity
- Pepper and Salt: common Computer Vision’s transformations that will set randomly chosen pixels to black/white
- Elastic deformation⁴
- Gaussian blur, which blurs the image with a Gaussian function
- Horizontal flip, which flips an image horizontally
These filters can be applied in three different ways:
- Only one (randomly chosen) filter f is applied to the original image i, producing a newly-created frame f(i) = i’
- Some of the filters are randomly chosen (along with their order) and applied to the original frame. This can be thought as a “chained” function application: fₙ …(f₂(f₁(i))) = iⁿ
- All the filters (their order is random) are applied sequentially on the input image

This GIF represents a man doing push-ups. This is our starting video: on it, we will apply the filters described above. Taken from here.






Starting from the upper left side, and going in order from left to right: Salt, Pepper, Multiply, Add, Horizontal Flip, Gaussian Blur, Elastic Deformation
Datasets
Test Set for the evaluation of the (pre-trained) 3D-ResNeXt and I3D
To evaluate the two chosen pre-trained NNs, I have extracted a subset of the Kinetics Test Set. This subset has been built by sampling 10 videos for each class among the 400 available classes, resulting in 4000 different videos.
Training/Test Set for the Fine-Tuned 3D-ResNeXt
The dataset employed to fulfill my original task is created by combining different datasets that can be found online.
The Test Set is built from the overall dataset taking, for each class, roughly the 10% of the total available samples, while the remaining 90% represents the Training Set (as shown below).
Distribution’s summary of the dataset used during Fine-Tuning
It is clear that we are looking at an unbalanced dataset. Since I do not have more data, to mitigate this problem, I will try to use a loss function called Weighted Cross Entropy, which we will discuss later on.
Manually-tagged Dataset for the Fine-Tuned 3D-ResNeXt
Finally, I have built and manually annotated a dataset consisting of some videos publicly available from YouTube.
Summary of the manually-tagged dataset. I can assure you that finding decent quality videos is — perhaps — more complicated than being admitted to the NeurIPS conference.
For this tagging-task, I have used a well-known tool called Visual Object Tagging Tool, an open source annotation and labeling tool for image and video assets. An example is shown below.
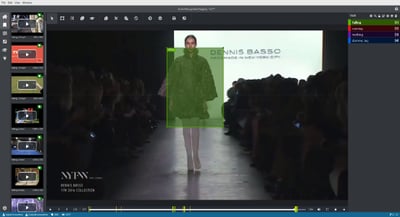
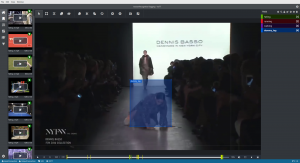
Tagging a video with the label falling. Tagging is mainly done in two sequential phases: first, tag the initial frame with the desired label; then, tag the final frame with a dummy tag, simulating the end of that action. Last, parse those “temporally-cut ranges” with a script, take the label (from the initial frame) and save the resulting clip. Et voilà!
Performance Analysis
Metrics and Indicators
For most of the results presented below, several metrics and indicators will be reported:
- Precision
- Recall
- F-Score
- Accuracy
- Mean and Standard Deviation of the prediction time for each K-frames batch (both measured in seconds).
Pre-trained 3D-ResNeXt vs Pre-trained I3D on Kinetics
The purpose of this test is to have a first, rough, overview. The only class we are interested into is jogging, while all the other labels represent actions that are completely different and useless for our goal.⁶
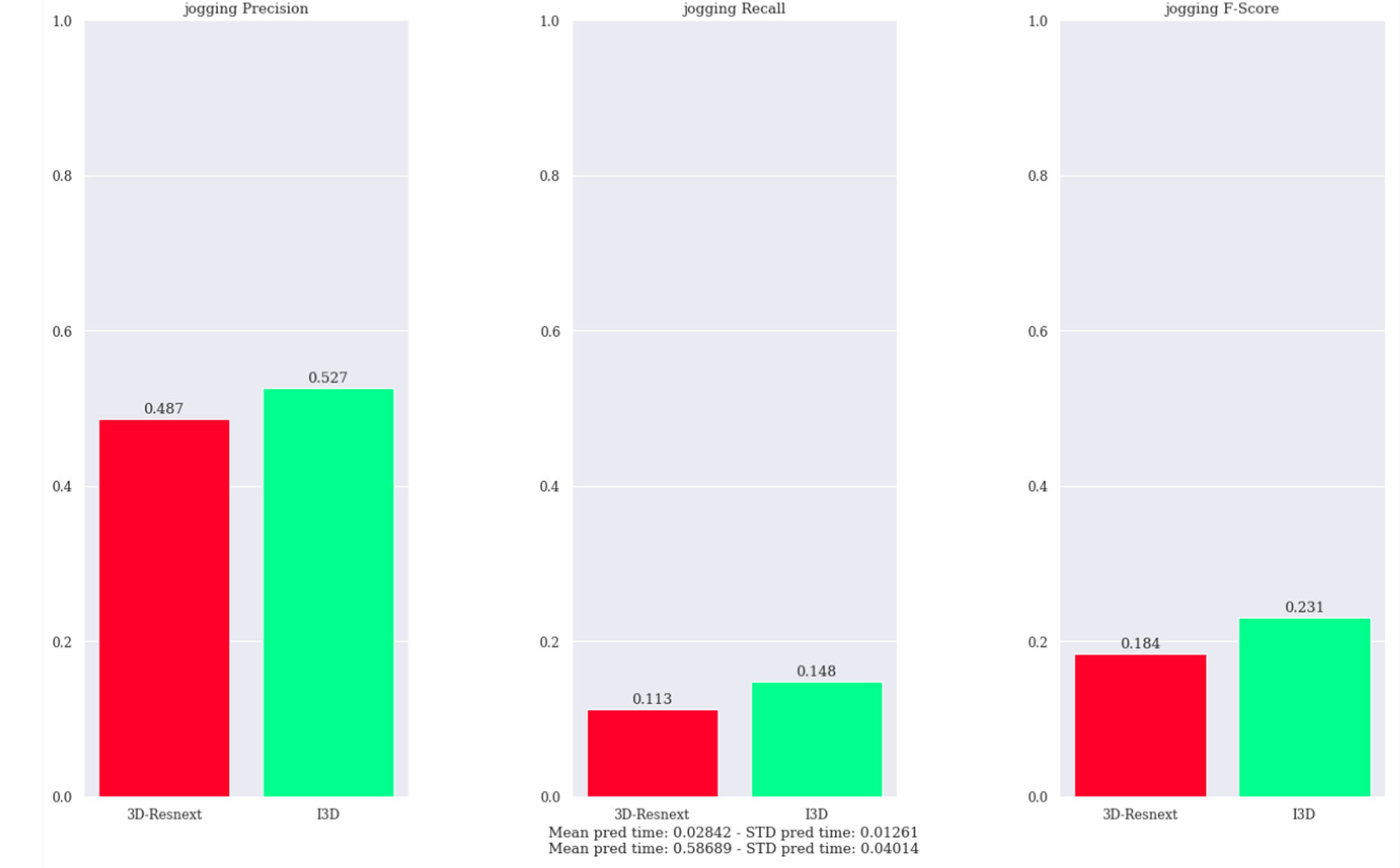
A first, rough, comparison between 3D-ResNeXt and I3D on the jogging class
Given this subset of data, the obtained results show that:
- the I3D seems to have better overall performances compared to the 3D-ResNeXt. This confirms its supremacy, in line with the results in the author’s paper
- the prediction time of the 3D-ResNeXt is competitive, while the I3D is too slow for a Real-Time setting, since its architecture is significantly heavier and complicated
At this point it is clear that, for our task, the 3D-ResNeXt is a better choice because:
- it is faster and almost capable of sustaining the speed of a 30 FPS video
- it has a simpler network architecture
- it does not need additional preprocessing or different inputs, since it uses only RGB frames
Fine-Tuned 3D-ResNeXt network’s performance on Test Set
Before stepping into the various parameter configurations, to take into account the Training Set’s unbalance, I use a different Loss Function called Weighted Cross Entropy (WCE): instead of giving each class the same weight, I use the Inverse Class Frequency to ensure the network gives more importance to errors on the minority class falling.
So, consider a set of classes C = {c₁ , …, cₙ}. The frequency fᵢ of a class cᵢ ∈ C represents the number of samples of that class in a dataset. The associated weight ICFᵢ ∈ [0, 1] is defined as:
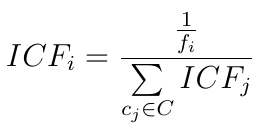
In the table below, I have reported almost all the training experiments I’ve been able to carry out during my thesis.
The parameters for the different Training runs of the 3D-ResNeXt (using Fine-Tuning). OA means Online Augmentation, while LR denotes the Learning Rate (the starting value is 0.01, and at a defined Scheduler Step — i.e. training epoch — it will be decreased by multiplying it with 0.1). It should be noted that I’ve tried some other parameter’s configurations, but these represent the best runs I’ve been able to analyze. As a related example, an interesting result is that, when using the OA in All mode, the network shows a lower performance: this could be caused by an overly-distorted input produced during the Online Augmentation.
The really big question before this work was: using the few data available for the falling class, will the network be able to have an acceptable performance? Given the parameters above, the obtained results are summarized in the chart below.
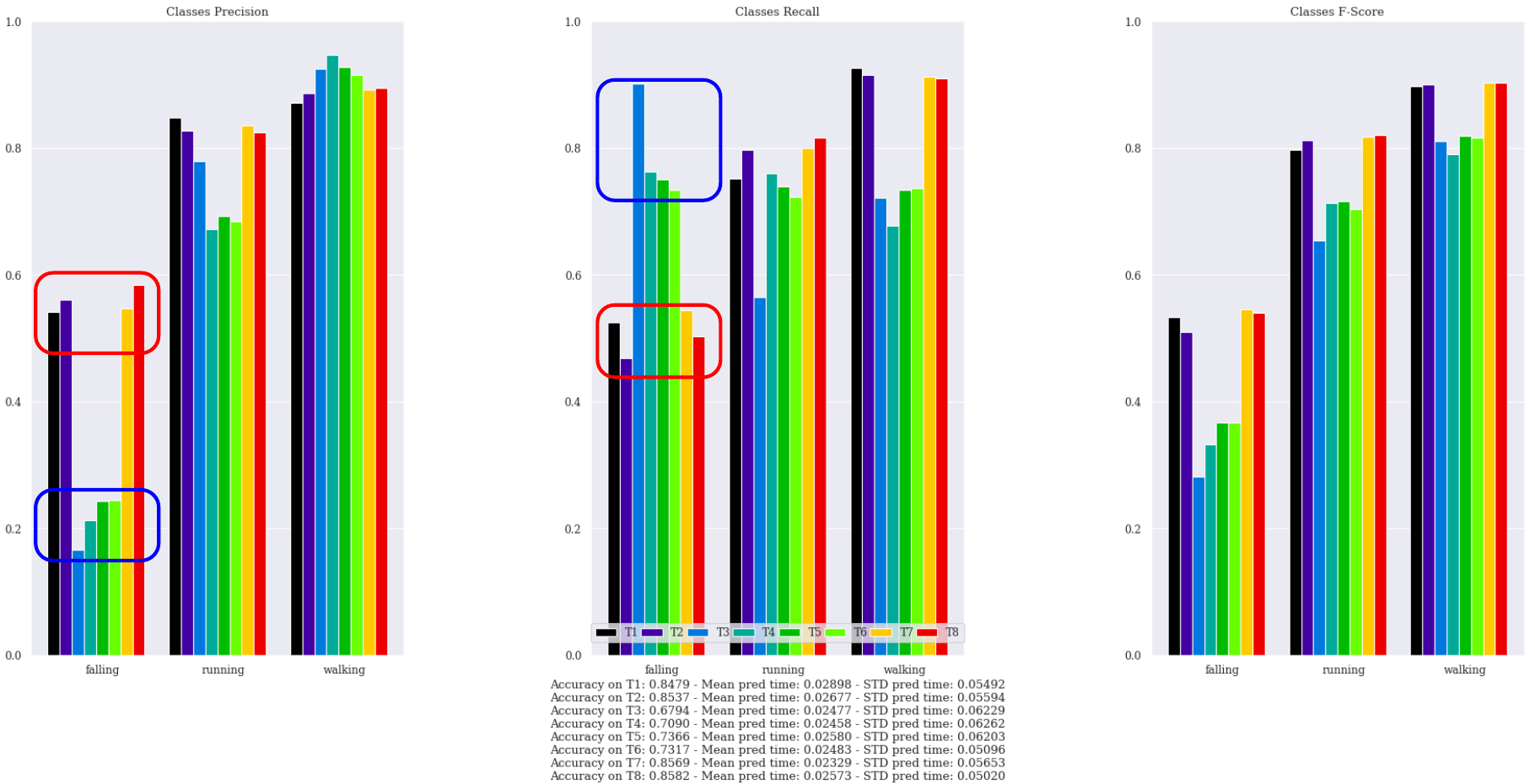
The performance of my Fine-Tuned networks on the Test Set
What can I say about that? The results seem pretty good: the network understands when someone is walking or running, while it is more doubtful when predicting falling. But, aside that, let us focus on the contoured blue and red rectangles: red denotes training runs with Cross Entropy, blue denotes training runs with Weighted Cross Entropy.
This chart highlights some interesting findings:
- When using Cross Entropy, the precision on the falling and running classes is noticeably better, and overall, the runs with Cross Entropy behave better, with a balanced precision-recall measures which are rewarded by the F-Score’s metric
- When using Weighted Cross Entropy, the precision on the minority class falling drops dramatically, while its recall increases significantly. During the evaluation, this concept translates in more frequent (and incorrect) falling’s predictions
TOP-3 Fine-Tuned NNs on the Manually-Tagged Dataset
Last, but not least — well, these are probably the most interesting and awaited results, am I right? — I have carried out a final test that aims to assess the capability of the Fine-Tuned NNs to generalize on unseen and real data. I have chosen the three best Fine-Tuned networks (their ID are T1, T7 and T8), taken from the previous experiment, and I have tested them on my manually-tagged dataset.
Drumroll — What will be the winning run? Will the nets be able to defeat overfitting, or will they be the victims? See you in the next episode — I’m kidding! You can see them below! ?
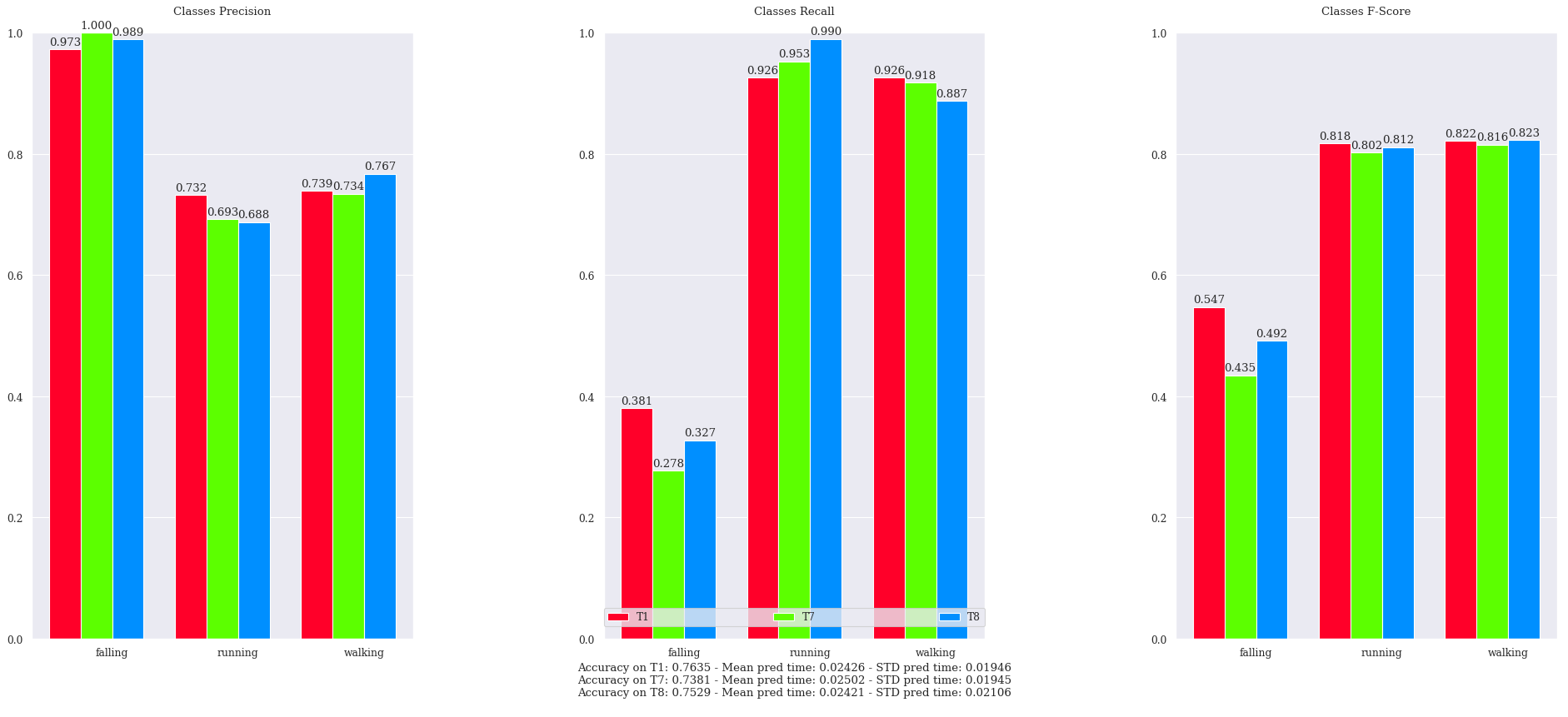
Performance of the three best training runs (T1 — T7 — T8) on the manually-tagged dataset
Finally, here they are! I’m actually surprised about them, since:
- The networks generalize quite well on the new manually-tagged dataset — I did not expect such good results! A stable F-Score of 0.8 is reached for the running and walking, with a satisfactory performance on the falling class
- Using Online Augmentation produces a positive effect on the recall of the minority class falling (T7 vs. T8)
- Less frequent use of LR Steps leads to a better overall performance. Indeed, the recall on the falling class (T1 vs. T8) has improved noticeably
- The three networks have a VERY HIGH precision on the falling class (T7 is never wrong!) but, unfortunately, they have a mediocre recall: they are very confident on the aforementioned label, but more than half of the time they cannot recognize a falling sample
What have I learned? What have YOU learned?
Finally, we have come to the end of our tortuous but satisfying journey. I admit it: it was tough! I hope this adventure has been to your liking, and thanking you for the reading, I leave here some useful take-home messages and future developments:
- The 3D-ResNeXt network is better suited for the Real-Time Human Action Recognition task since it has a dramatically faster prediction time than the I3D
- The CE and WCE produce radically different results on the minority class falling, while they do not change so much the other two classes: the first produces a well-balanced precision and recall, the latter causes the trained network to predict more frequently the minority class, increasing its recall at the expense of its precision
- The Online Augmentation helps the network to not overfit on training data
- A LR that changes more rarely is to be preferred to a LR that changes more frequently
- Speaking broadly, the result that has emerged during training is not an “absolute truth”: there are some cases where the task requires a higher recall rather than a higher precision. Indeed, based on it, we might prefer a network that predicts falling:
* more precisely but more rarely (more precision, less recall)
* less precisely but more frequently (more recall, less precision).
Future Developments
- The minority class is maybe too unbalanced. More and high-quality data
(not necessarily only for one class) could dramatically increase the network’s performance - The WCE has enormously increased the recall of the minority class. It could be interesting to investigate more on this behaviour or to try another weighting method that reduces the loss’ weight on the minority class. This could potentially make the network to predict less frequently the class falling, thus increasing its precision with also the benefits of a higher recall
- The predictions made by the network could be joined with another system that is able to detect people (whose task is known as People Detection), in order to give a more precise and “bounded” prediction. However, this could require a different dataset, where the input videos contain only the relevant information (e.g. a man or woman falling with minimal or no background or environment)
[youtube v="o7MAr8U4Un0"]
...
[1] Human Action Recognition and Prediction: A Survey. Yu Kong, Member, IEEE, and Yun Fu, Senior Member, IEEE — JOURNAL OF LATEX CLASS FILES, VOL. 13, NO. 9, SEPTEMBER 2018. Link
[2] Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh, 2017. Link
[3] João Carreira and Andrew Zisserman, Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset, 2017. Link
[4] Simard, Steinkraus and Platt, “Best Practices for Convolutional Neural Networks applied to Visual Document Analysis”, in Proc. of the International Conference on Document Analysis and Recognition, 2003. Link
[5] The prediction time does not take into account the preprocessing time. For 3D-ResNeXt, it is minimal, while for I3D, it is much more lengthy due to the calculation of the optical flow for each input video. As an example, with my specs, 10 seconds of a single video need about 1 minute of preprocessing.
[6] It’s completely fine if you think that this test is simplistic and not very accurate. Due to time and space limitations (those videos were literally eating my free disk space), and also because this is completely out-of-scope, I managed to run these tests only on a small portion of test data.
Written by Eugenio Liso - Agile Lab Big Data Engineer
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!