320% data projects ROI $6M Efficiency Savings 40% Less Data Duplication 3x Data Projects Development 50% Time Saved in Delivery
with Witboost
Empowering Large Enterprises with Witboost
Explore the significant effects of Witboost's performance over a three-year span as evaluated by Forrester Research


Craft your own standards and automate your data practice
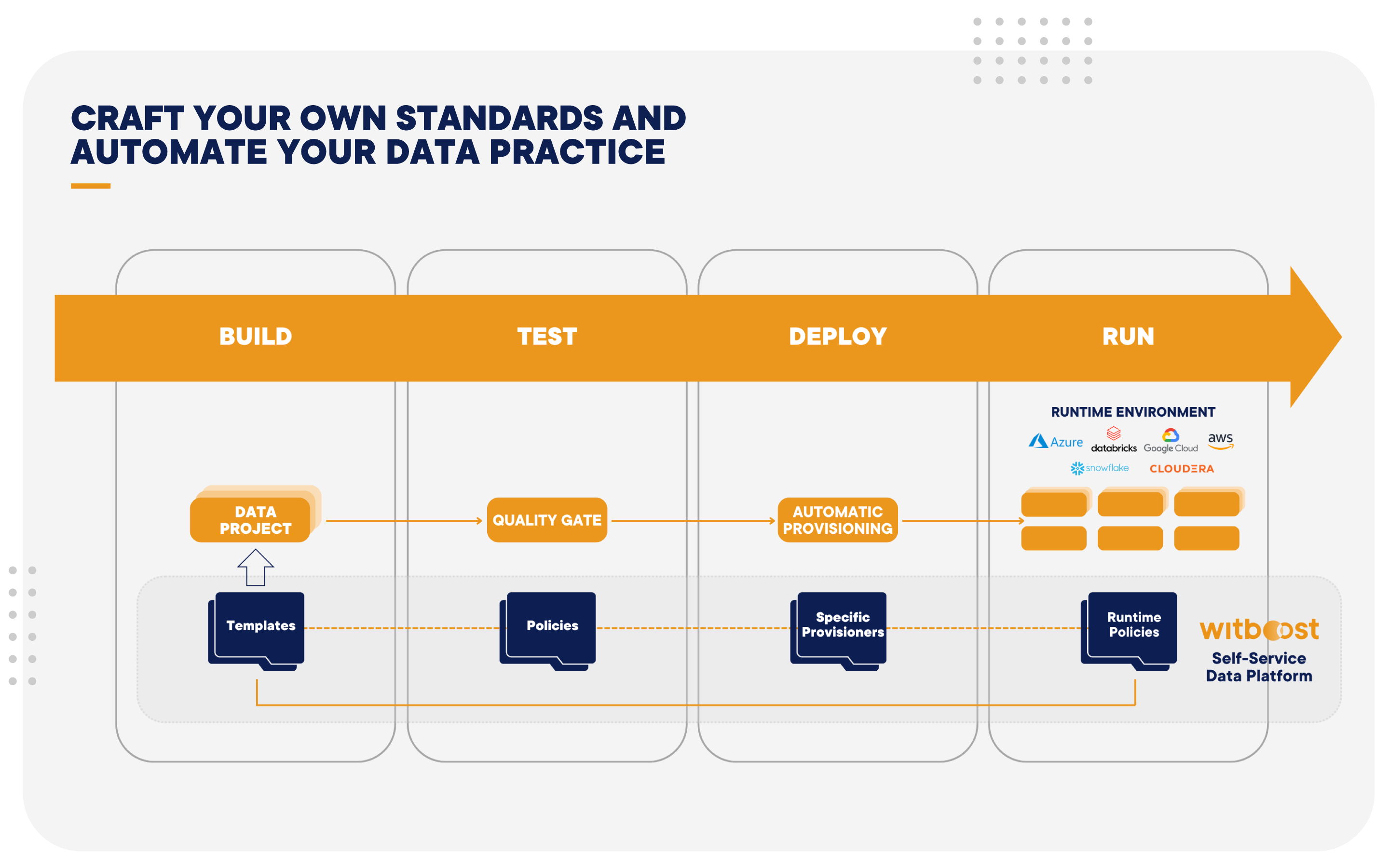
Witboost is a pioneering platform streamlining complex data projects across various platforms, enabling seamless data production and consumption. This unified approach empowers you to fully utilize your data without platform-specific hurdles, fostering smoother collaboration across teams.
It seamlessly blends business-relevant information, data governance processes, and IT delivery, ensuring technically sound data projects aligned with strategic objectives. Witboost facilitates data-driven decision-making while maintaining data security, ethics, and regulatory compliance.
Moreover, Witboost maximizes data potential through automation, freeing resources for strategic initiatives. Apply your data for growth, innovation, and competitive advantage.