Data Mesh
How to identify Data Products? Welcome “Data Product Flow”
How do we identify Data Products in a Data Mesh environment? Data Product Flow is can help you in answering the question.
How and why successful data-driven companies are adopting Data Mesh
Paradigm shift
Every once in a while, a new way of doing things comes along and changes everything. Sometimes this takes the form of new technologies, infrastructures, services. Some other times, the slack arises as an urgent need from the market itself. While the former needs engineering teams to push the change, the latter is very likely an “ask for help” straight from the business, and that’s the most powerful engine industry can have.
As the data-* (management, processing, governance, …) ecosystem gained its momentum in the last ten years, more and more companies invested in becoming “data-driven” after the early adopters demonstrated how much value data could generate. This wave enabled the development of all the Big Data and Cloud technologies/standards/services we very well know and use today.
This “gold rush for data” focused on opening silos and centralizing data into platforms, lakes, pushing faster and faster towards distributed architectures, hybrid clouds, even transitioning from IaaS to PaaS to SaaS. But it lacked attention to aspects like data ownership, data quality assurance, scalable governance, usability, trust, availability, and discoverability of data, which are the key factors that allow consumers to find, understand, and safely consume data to provide business value.
Data Mesh is a paradigm shift that arose as a need from “the fields” from the actual world of monolithic data lakes/platforms. It can be considered revolutionary for the results it promises and evolutionary, as it leverages existing technologies and is not bound to a specific underlying technology.
It is an organizational and architectural pattern leveraging domain-driven design, that is the capability of designing data domains that are very much business-oriented instead of being technology-oriented. We can see this paradigm shift on data as analogous to when monolithic web-services transitioned to domain-driven-designed micro-services.
When Data Lake becomes Data Mess
To better understand the main advantages of Data Mesh and its architectural principles, we need to take a step back and look at what was (and in most cases still is) state-of-the-art for data management before this new paradigm.
In the last years, data management’s main trend has been to create a single, centralized Data Lake (often built on-premise) to achieve both centralized data governance and a centralized processing platform. While the former proved successful, despite significant technology investments, the latter became counterproductive, both from organizational and technical points of view, for several reasons.
When creating Data Lakes, the first mantra was to open the silos, which meant setting up as soon as possible ingestion pipelines to bring data from the external systems to the data lake. The data lake’s internal data engineers team usually had the accountability to design these processes. The integration effort was undertaken from a systems point of view, i.e., let’s understand how we can take data in external systems and bring it into the data lake. This happened to occur via the broadest variety of special-purpose or generalized ETL (Extract, Transform, Load) jobs or CDC (Change Data Capture) tools. Once the integration was set up, the data ownership fell automatically in the hands of the data engineering team, who usually did not pay so much effort in first agreeing with the source systems on data documentation, data quality, etc., thus resulting in extra effort to implement checks, metrics, data quality measurements on “not-so-well-known” data.
This integration-based approach leads to even worse scenarios when something about the source system mutates: schema changes, source domain specifications evolving, GDPR introduction, you name it … It is a model that cannot scale up, especially for multinational corporations centralizing data from different branches/countries and related laws/regulations, because source systems are not aware of the process of data warehousing, they don’t know about data consumer needs, they are not focused on providing data quality on their data because it’s not their business purpose. This usually sets the scene for disengagement in creating added value for the overall organization.
Another classical problem of Data Lake is the layered structure, where layers are typically technical (cleansing, standardization, harmonization). You can look at these layers as a fixed amount of overhead between data and the business needs that are continuously slowing down the process of value creation.
Data Mesh overview
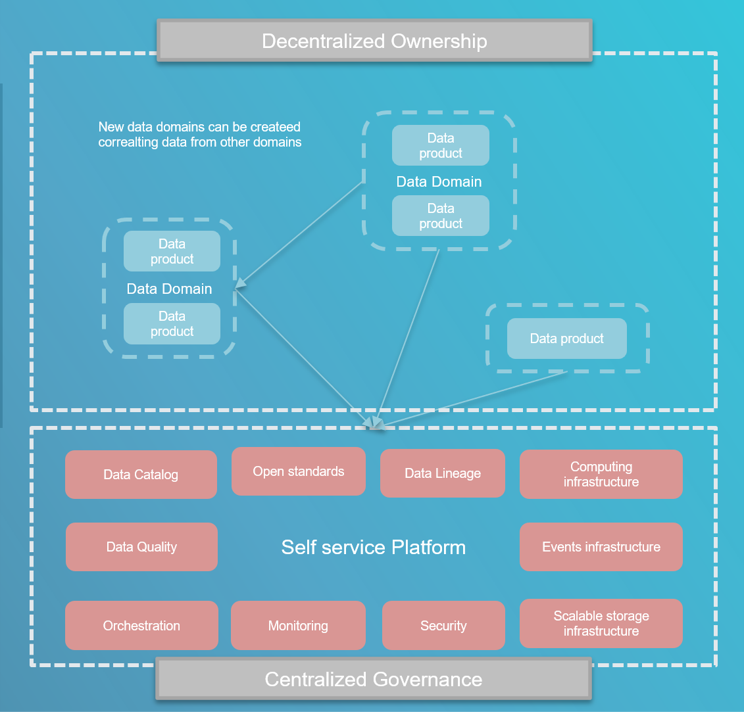
Data Mesh is now defined by 4 principles (according to Zhamak Dehghani):
To understand what is changing compared with the past, it is useful to start by changing the vocabulary. In Data Mesh, we talk more about serving than ingesting, as it is more important to discover and use data rather than extract and load it.
Every movement or copy of the data has an intrinsic cost:
Often the data movement or copy is needed for the following reasons:
Keep in mind that data movement/copy is not data denormalization. Denormalization is quite normal when you have multiple consumers with different needs, but this does not imply a transfer of ownership.
When you move data from a system/team to another, you transfer the ownership, and you are creating dependencies with no added value from a business perspective. Data Mesh transfers data ownership only when data is assuming a new functional/business meaning.
Data Mesh paradigm is also instrumental in “future-proofing” the company when new technologies emerge. Each source system can adopt them and create new connectors to the scaffolding template (we will go deeper on this in the next articles), thus maintaining coherence in providing access to their data for the rest of the company through Mesh Services.
Data Mesh adoption requires a very high level of automation concerning infrastructure provisioning, realizing the “so-called” self-service infrastructure. Every Data Product team should be able to autonomously provision what it needs. Even if teams are to be autonomous in technology choices and provisioning, they cannot develop their product with access to the full range of technologies that the landscape offers. A key point that makes a data mesh platform successful is the federated computational governance, which allows interoperability through global standardization. The “federated computational governance” is a federation of data product owners with the challenging task of creating rules and automating (or at least simplifying) the adherence to such regulations. What is agreed upon by the “federated computational governance” should, as much as possible, follow DevOps and Infrastructure as Code practices.
Each Data Product exposes its capabilities through a catalog by defining its input and output ports. A Data Mesh platform should nonetheless provide scaffolding to implement such input and output ports, choosing technology-agnostic standards wherever possible; this includes setting standards for analytical, as well as event-based access to data. Keep in mind that it should ease and push the internally agreed standards, but never lock product teams in technologies cages. The federated computational governance should also be very open to the change, letting the platform evolve with its users (product teams).
Data Product standardization is the foundation to allow effortless integration between data consumers and data producers. When you buy something on Amazon, you don’t need to interact with the seller to know how to purchase the product or know which characteristics the product has. Product standardization and centralized governance are what a marketplace is doing to smooth and protect the consumer experience.
On this topic, you might be interested in the 10 practical tips to reduce Data Mesh’s adoption roadblocks, or you can learn more about how Witboost can get your Data Mesh implementation started quickly.
How do we identify Data Products in a Data Mesh environment? Data Product Flow is can help you in answering the question.
Companies commit errors by staking their Data Mesh implementation on technology when the entire paradigm shift is based on a technology-agnostic...
When it comes to modelling Data Products people go into panic. There are no clear rules, only some conceptual and not actionable indications.