In this article we address the mistake companies make by staking their Data Mesh implementation on technology when the entire paradigm shift is based on a technology agnostic approach.
In this article
- Why designing a Data Mesh with one technology/data platform is wrong
- The Data Vendor market risk
- Do we really want the Data Mesh to be another silo?
- Interoperability is a crucial concept. Here's what it means:
- Wrapping up
A Data Mesh implementation (like every significant transformation) should survive for a minimum of 10–15 years, possibly even more. Are you planning for that?
During the past months, while Data Mesh is becoming increasingly popular, I have seen many people and companies sharing their architecture to implement the Data Mesh paradigm.
It is hard to deeply understand a Data Mesh implementation from some diagram posted on LinkedIn, a marketing statement or a conference presentation. I may be wrong, and my worries are not founded.
You need to leverage some technology to implement a Data Mesh at a certain point. Still, I fall off from the chair when I see that some company is implementing a Data Mesh with just one technology or data platform, leveraging all native capabilities.
Why designing a Data Mesh with one technology/data platform is wrong
When I see that, immediately tons of questions raise in my mind about Data Mesh implementation:
- How can they expose observability and control ports if that platform is not exposing API?
- How can they enable output port polyglotism if the platform only exposes tables, topics, or whatever?
- Are they imposing the technology on all the domains that want to be part of the mesh? Is this real decentralization, autonomy and ownership?
- How are they bundling infrastructure, data, metadata and code to create an atomic and independently deployable unit
- Are they creating data product experiences, or do they stick with facilities provided by the platform?
- Did they read the principles and decide to take only the easy and cool parts?
I can go on for hours asking myself if they are oversimplifying or if I’m overcomplicating the problem. For sure, case by case, both could be true.
But there is one aspect I can’t tolerate about implementing a Data Mesh with a single technology or data platform. Data Mesh is a strategic and transformative initiative; it is an evolutionary architecture that must embrace the change and survive even a core technological change; Strategic thinking should take risks and unexpected evolution into account.
Data Mesh has the goal of generating business value in the long term. It is not a quick win. The investment to embrace the Data Mesh paradigm is enormous and will stand for years, so we need to guarantee the persistence of the results and ROI.
A Data Mesh implementation (like every significant transformation) should survive for a minimum of 10–15 years, possibly even more. Are you planning for that?
The Data Vendor market risk
Nowadays, the market of tools in the Data Management space is skyrocketing, VCs inject vast amounts of money, and quotations reach nonsense multipliers.
The competition is brutal; we have tens of data platforms and tons of tools with overlapping capabilities, all heavily funded by VC and most definitely not at breakeven.
We have already seen an entire market segment collapse during the past years. In the early years of Hadoop, we had 5–6 distributions, but after a bunch of years, only one survived.
In the case of MapR, they had a good customer base with important customers; in 2014, they raised 110M, and in 2019, they shut down the company. Their strategy was to pair the classical Apache-based projects with their components (someone will remember mapr-db, mapr-streams, etc.).
Those components were deeply integrated into the platform and offered competitive advantages, so many users adopted them. After the shutdown, the migration from those components was a nightmare because there was no interoperability with other technologies and no other vendors supporting them, requiring a complete rewrite of all use cases.
How many companies that got massive funding in the past three years will still be around in 5–10 years?
We also need to think that well-established companies with solid revenues and customers have more difficulties innovating because they have more legacy. Will they be able to resist newcomers?
Also, new practices and patterns will rise, improving performances and user experiences. Are you ready to embrace them, or do you need to wait for the vendor to do it?
In 2019 Barr Moses and Lior Gavish founded Montecarlo Data, and in 2022 it is a unicorn and overtaking any other tool active in the Data Quality landscape for the past 20 years. It is an example of the speed of the market we need to face.
When a market is making significant movements quickly, it has high volatility. In most cases, volatility is a risk indicator.
Your Data Strategy should be de-correlated to market risks (in this case, the market of data platform vendors) because the goal is to generate business value for your company. This value should not be affected by external factors as much as possible.
This crazy market is already hitting your company. People in your organization will always ask for more advanced and excellent tools as soon as they gain traction. Can you switch your existing tools? Can you make them interoperate with the old ones?
If you can’t and try to resist the innovation spirit of people, you will end up with IT shadowing (definitely something not good). Also, a single Data Platform can’t be the best option for all the use cases, or at least it will not be the best in the future as soon as some competitor focuses more on a particular area.
Are you protecting yourselves as much as possible, creating abstractions, limiting the lock-in, adopting open interfaces/protocols, or decoupling tools, components, practices and processes?
Do we really want the Data Mesh to be another silo?
Let’s imagine this scenario. I’m a big enterprise.
I already went through DWH and Data Marts, adopted the Data Lake, and now planning to move toward the Data Mesh.
For the DWH, ten years ago, I selected a specific vendor; I created everything within the platform, including the whole business logic implemented with a particular dialect of SQL and proprietary PLSQL. I built everything there for five years, but I hit some issues around scalability, ingestion rates, and time to market at a certain point.
Then five years ago, I decided to leverage a Data Lake-oriented platform to address some use cases requiring it to be cost-effective and to scale indefinitely at PB scale. I went with a Hadoop distribution or similar. While I was implementing such massive use cases and enjoying the new computing power, I realized the need for the following:
- New tools (data exploration, data quality, data catalog, etc.) not making the strong assumption data are stored in an RDBMS and accessible through SQL. But those new tools are making other strong assumptions too.
- New skills to exploit the computing polyglotism I now have.
- New governance rules and processes because the data lake has different requirements, needs and goals.
- Duplicate the data and the business logic from the DWH to the Data Lake because data are strongly interconnected, and to create new use cases, I need a considerable amount of them.
But once you are in the game, you have to play, so the Data Lake initiative, with the original aim to unlock new business insights and to enable ML/AI in the company, turned into a completely new Data Platform with a different tech stack, skills, processes and policies. The original CAPEX investment has tripled, while OPEX costs have multiplied tenfold.
The data duplication across different technologies generates much confusion around data ownership and master data management. We have two giant silos fighting for budget and use cases, offering the worst-ever user experience for data consumers with everything duplicated.
Do you know why I have silos?
It happened because of technology lock-in. Let’s try to analyze it.
- First of all, I coupled teams with technology, and created a team to manage the Data Lake, so meanwhile, they had problems; they tried to solve their issues by buying tools and setting up their processes.
Conway’s law in action here, the system architecture will align with the organization, so if I have two siloed teams, I will end up with two data silos anyway. Don’t couple teams with technology; couple them with objectives.
Why did I create a new team for the Data Lake? Because I needed new and different skills to manage the latest technology. It was the easiest way and the technology drove it.
- Please pay attention that it is a matter of interoperability. If my tools (referring to Data Quality, Data Catalog, Access Control, etc.) are coupled to a specific technology to do their job, they increase the lock-in and the barrier to interoperability.
When changing the core technology, I must also change all the related tools. Run away from tools working only for specific technologies such as Snowflake, Cloudera, Oracle, Kafka, etc. It is even more dangerous when I build applications using frameworks coupled with one of them. I am bundling my business logic to a data storage technology…if I want to change the storage technology, I must also rewrite all the applications (crazy).
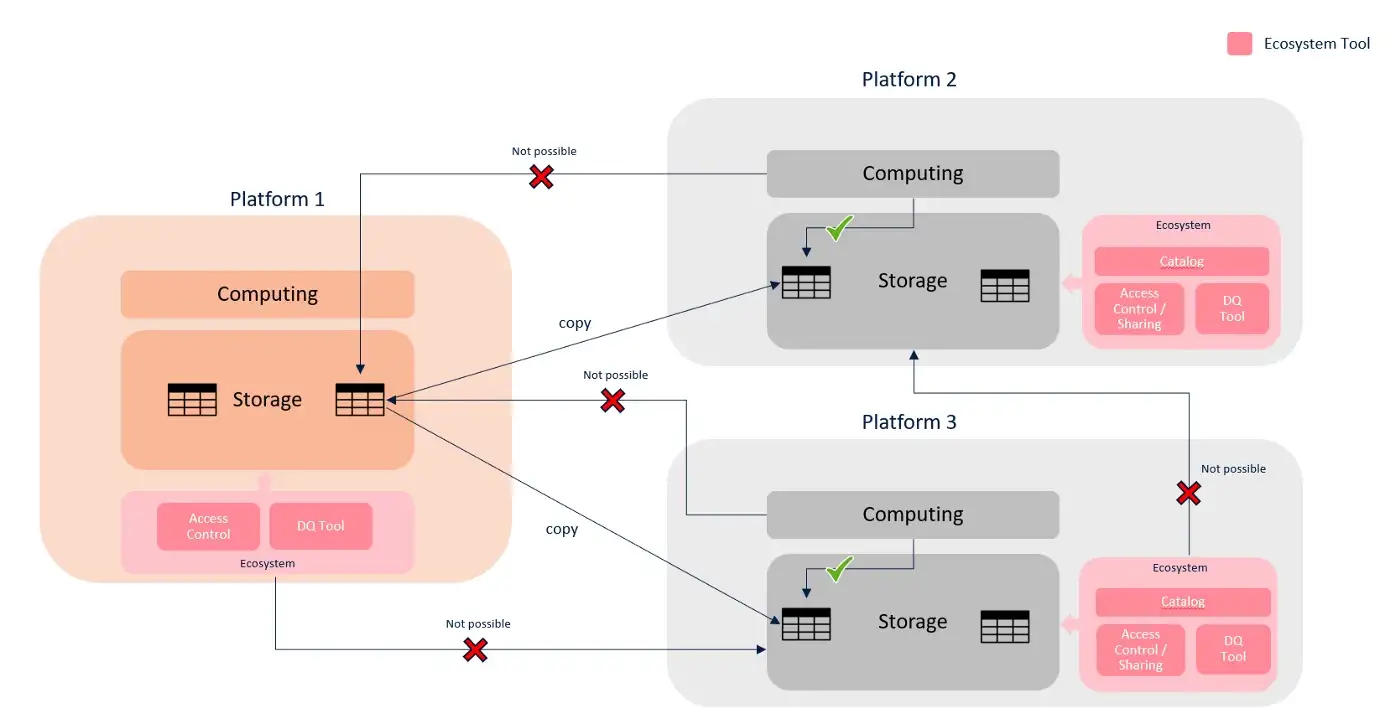
Now I want to implement the Data Mesh, and from a technology standpoint, I have many options:
- I select a new all-in-one technology platform (the third one), plan for a significant migration, rewrite everything, and the migration will never end. This third platform offers lots of native capabilities and proprietary interfaces. I use them to speed up the time to market, and it will turn into another silo because of the lack of interoperability.
- Re-use one of the existing platforms, changing the practice, and reducing the impacts but still locking me into a silo with no capabilities to expand and evolve my technological landscape for the future.
- I create my own interoperability standards, abstracting technology and products, leveraging open protocols, and assembling the components I need. It allows me to leverage existing technology or introduce new ones in the future, also helping the transition from the as-is to the to-be. Regarding business logic development, I use only frameworks highly independent of the data storage technology to reduce the overall coupling.
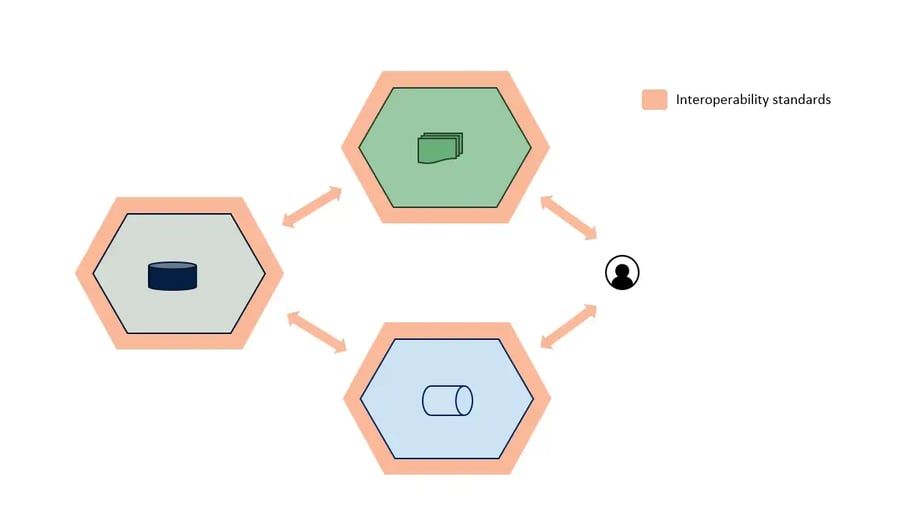
Interoperability is a crucial concept. Here’s what it means:
- Having clear standards for exchanging any information related to a data product (data, metadata, observability info, other)
- Those standards should be open, extensible and not coupled with a specific technology.
- Information exchange should include data formats, metadata and protocols.
It is also essential to have the possibility to add new interoperability standards along the way.
This way all the ecosystem’s tools will no longer be coupled to a specific platform or technology. Still, we will integrate them with interoperability standards as well.
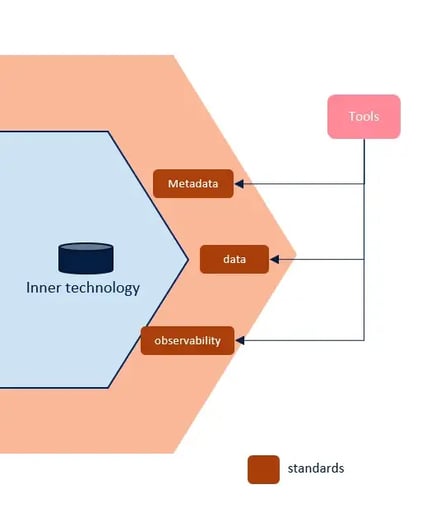
Wrapping up
When implementing a Data Mesh, you shouldn’t leverage a single data platform or technology by design; plan the Data Mesh to embrace the change and make it sustainable.
You can use one platform/technology as the main backbone or achieve a first MVP, but please pay attention to the following aspects:
- Don’t use native facilities (offered by tools) to set interoperability standards. Even if you have just one technology right now, design everything to be able to change it or add one without breaking contracts and standards.
- Decouple storage capabilities from computing ones. You should be able to process the data stored somewhere in multiple ways, and you should be able to process data stored in various places without the need to move/copy them.
- Try to be declarative as much as possible, adopting open standards. In any case, your standards are better than the vendor ones.
- Rely on open and widely adopted protocols to share data across data products on output ports.
- Set your standards for control port and observability API.
- Don’t couple governance and security processes/policies with specific technologies/data platforms.
- Focus on practice and developer experience more than tools and technologies.
Posted by Witboost Team
LinkedIn
The Data Mesh journey is long and requires proper implementation to get it right. Grab our white paper on successful Data Mesh implementations and avoid making the mistakes mentioned in this article!