Scania's Evolution toward Data Mesh

How Poste Italiane Leads it Journey to Data Mesh

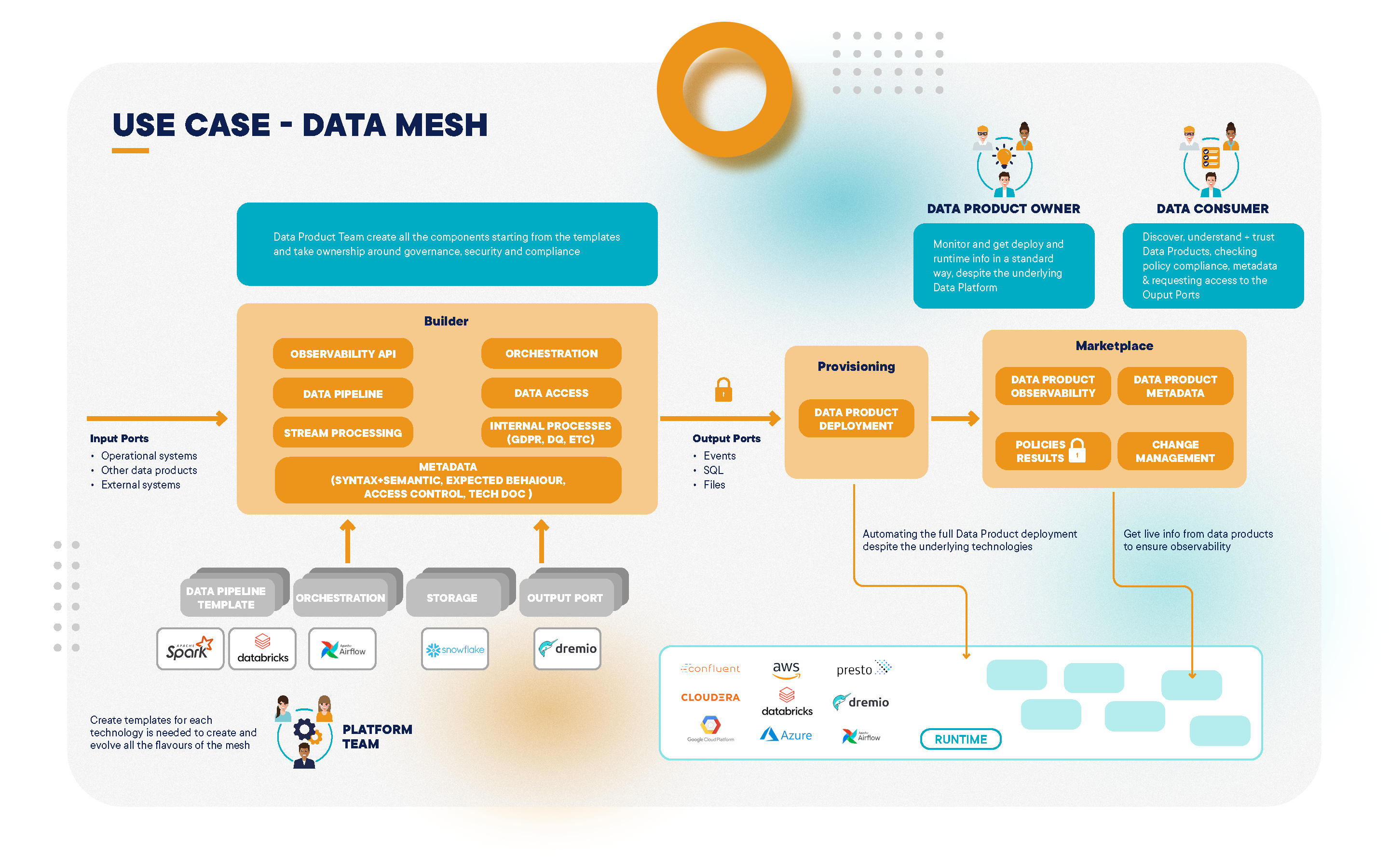
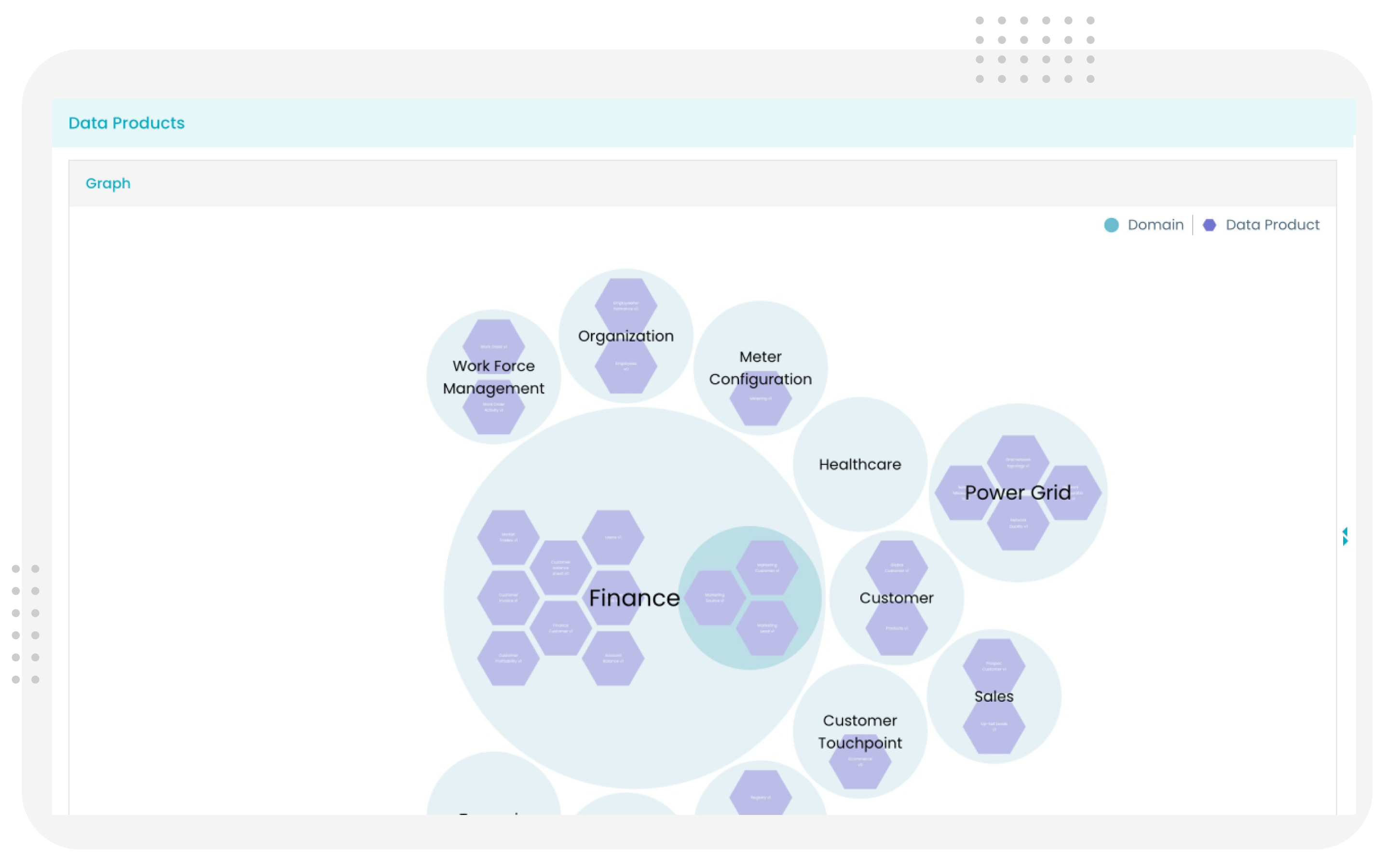
How Enel Group Built a Data Mesh Architecture


Watch the video to learn more about Scania's Data Mesh evolution.


Learn more about Enel Group's Data Mesh architecture.


Learn more about Poste Italiane's Data Mesh Implementation.