1. Classifying and Securing Sensitive Data
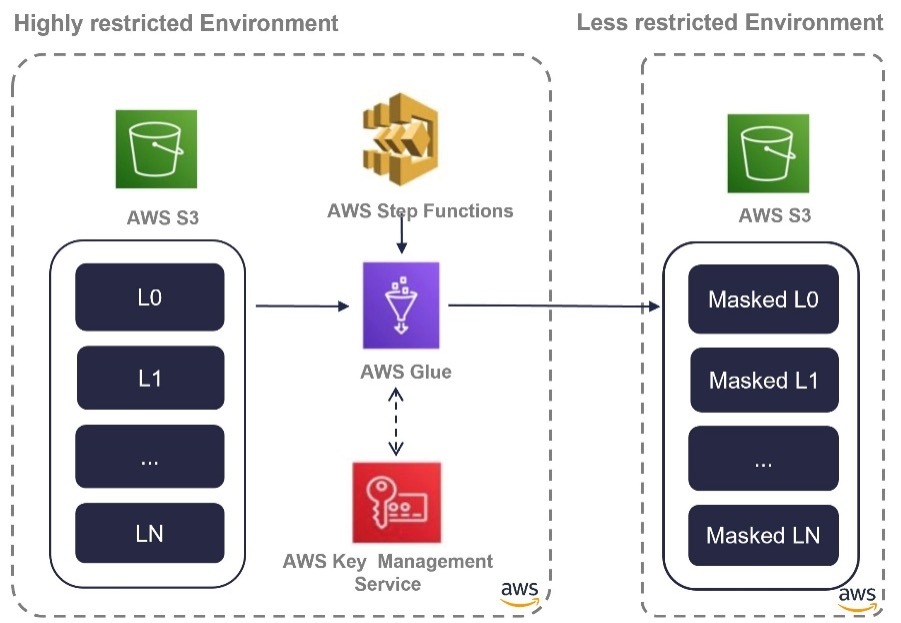
The first step focused on ensuring that personally identifiable information (PII) could be reliably identified, classified, and safeguarded within the data lake environment. This secure foundation established the strict boundaries needed to enforce governance and privacy requirements from the very start.
2. Encrypting and Masking with Format Preservation
Sensitive data was protected using format-preserving encryption (FPE), ensuring that PII remained secure while preserving referential integrity. This approach allowed encrypted values to maintain their original structure, enabling seamless use in downstream processes without exposing the actual information.
The Anonymization Key was stored in the highly restricted environment, and was not subjected to sharing or activity that could have compromised its security.
3. Enabling Safe Data Consumption
With PII securely masked and encrypted, developers and analysts were able to work with consistent, anonymized datasets in a development-ready environment. This ensured compliance while still supporting reliable analytics, enabling teams to conduct daily operations without risking sensitive information exposure.
The first step focused on ensuring that personally identifiable information (PII) could be reliably identified, classified, and safeguarded within the data lake environment. This secure foundation established the strict boundaries needed to enforce governance and privacy requirements from the very start.
Sensitive data was protected using format-preserving encryption (FPE), ensuring that PII remained secure while preserving referential integrity. This approach allowed encrypted values to maintain their original structure, enabling seamless use in downstream processes without exposing the actual information.
The Anonymization Key was stored in the highly restricted environment, and was not subjected to sharing or activity that could have compromised its security.
With PII securely masked and encrypted, developers and analysts were able to work with consistent, anonymized datasets in a development-ready environment. This ensured compliance while still supporting reliable analytics, enabling teams to conduct daily operations without risking sensitive information exposure.