Media
Is Data Mesh the future of Data Engineering?
Is Data Mesh the future of Data Engineering? Roberto Coluccio, Data Architect at Agile Lab tries to answer the question.
A new wave is coming in the field of Big Data technologies: real-time Data-Lakes and low-cost DWHs.
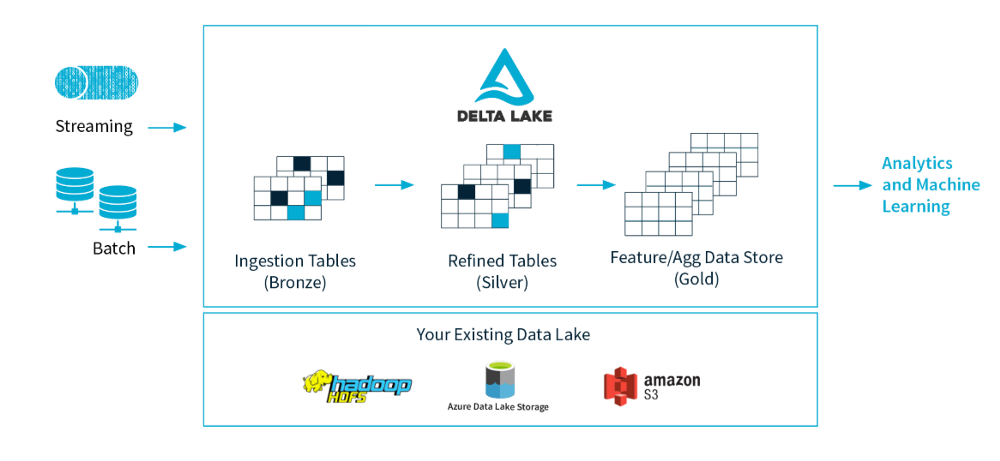
“A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale”
After two years of apparently no innovation in the field of Big Data technologies, now a new wave is coming: real-time Data-Lakes and low-cost DWHs.
The first one is the possibility to feed a DataLake in real-time directly from operational data sources and reducing the time of data availability from many hours to a few minutes. This is a game-changing pattern because it will enable new patterns in the data value chain.
The second one is related to the possibility to apply complex data transformation without being limited by append-only operations and strict immutability. The possibility to have data lakes and DWHs sitting on top of the same resources, tools and practices, is a huge gain in terms of TCO and consolidation of past investment to adopt big data technologies.
DWH is usually bringing the following challenges:
Now a unified platform for both data lake and DWH is possible and we can also feed it in real-time with fast update cycles.
Main problems with current architectures for Data Lakes
Anyway leveraging big data technologies to build data lakes is still the cheapest ( in terms of TCO ) way to go, then market leaders like Databricks, Uber, Netflix invested a lot of resources to bring such technologies a step forward.
Table Format
The main problem is due to the old conception of the schema-on-read pattern. We were used to thinking about a *file format* and some schema-on-read provided through an external table with Hive or Impala. In this scenario table state is stored in two places:
This is creating problems for the atomicity of various operations and it is also affecting schema evolution because the ownership of the schema is on HMS from a definition standpoint, but rules for evolution are tightly coupled on capabilities of the file format ( ex. CSV by position, Avro by name ).
A table format is like an intermediate level of abstraction where all concepts related to the table (metadata, indexes, schema, etc ) are paired with data and handled by a library that you can plug inside multiple writers and readers. The processing engine is not owning table info anymore, it is just interpreting them coming from the table format. In this way, we will be decoupled by processing engines, file formats, and storages ( HDFS, S3, etc ).
This is opening interesting new perspectives.
Delta Lake
Delta Lake has been started and then open-sourced by Databricks.
The main concept in delta lake is that everything moves around a transaction log, including metadata. This feature is enabling fast file listing also in large directories and time travel capabilities.
Delta Lake
Delta Lake is designed for Spark and with streaming in mind. The deep integration with Spark is probably the best feature, in fact, it is the only one with Spark SQL specific commands ( ex. MERGE or VACUUM ) and it introduces also useful DMLs like “UPDATE WHERE ” or “DELETE WHERE ” directly in Spark.
In the end, having ACID serializability properties, we can now really think to move a DWH inside a Data Lake. That’s way Databricks now use the term DataLakeHouse to better represent this new era.
Hudi
In early days Uber was a pioneer in standard big data and data lake architectures, but then its challenging use cases triggered new requirements in terms of data freshness, and also they had to face an important cost reduction need. In some scenarios, they realized that every day they were rewriting 80% of their HDFS files.
Therefore, they hope to design a suitable data lake solution, which can achieve fast upsert and streaming incremental consumption under the premise of solving the needs of the general data lake. This was the start of Hudi.
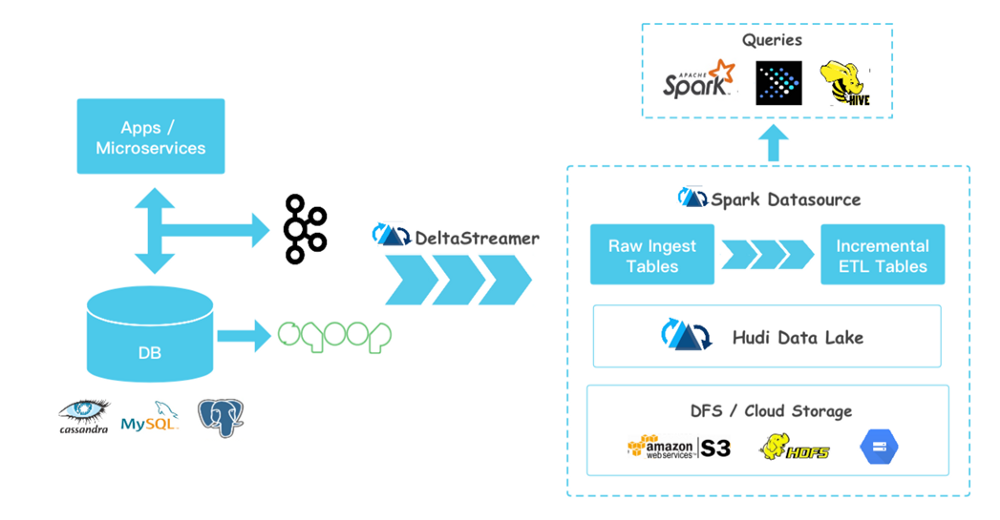
The Uber team implemented two data formats, Copy On Write and Merge On Read, on Hudi.
Merge On Read was designed to solve their fast upsert. To put it simply, each time the incrementally updated data is written to a batch of independent delta file sets, the delta file and the existing data file are periodically merged through compaction. At the same time, it provides three different reading perspectives for the upper analysis engine: only read delta incremental files, only read data files, and merge read delta and data files. Meet the needs of various business parties for data batch analysis of data lakes.
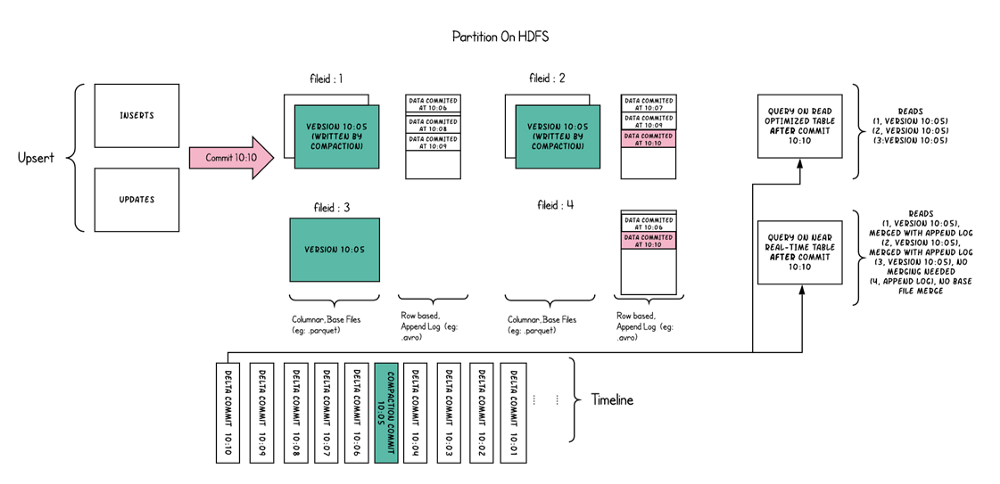
Copy on write instead is compacting data directly in the writing phase, then it is optimized for the read-intensive scenario.
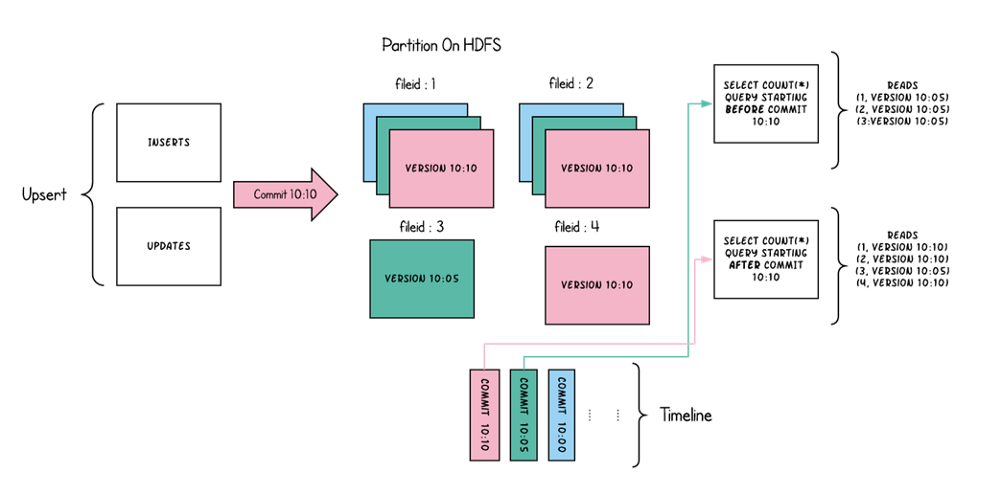
The flexibility to choose how to tune the system is probably the greatest functionality of Hudi. Wrapping up:
Iceberg
Netflix, in order to solve previously mentioned pain points, designed its own lightweight data lake Iceberg. At the beginning of the design, the authors positioned it as a universal data lake project, so they made a high degree of abstraction in the implementation. Although the current functions are not as rich as the previous two, due to its solid underlying design, once the functions are completed, it will become a very potential open-source data lake solution.
The key idea is simple: track all files in a table over time leveraging a concept of metadata snapshot tracking. The table metadata is immutable and always move forward.
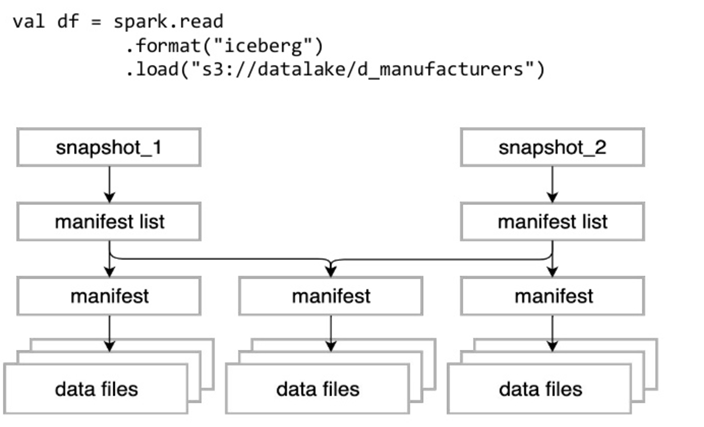
What is stored in Manifest File:
Basic data file info
Values to filter files for a scan
Metrics for cost-based optimization
Such a rich metadata system allows skipping completely any kind of interaction with the DFS ( potentially expensive or eventually consistent ). Also, query planning is leveraging these metadata for fast data scanning
Comparison
In the following section, we try to analyze all of them from different points of view, starting from a general perspective.
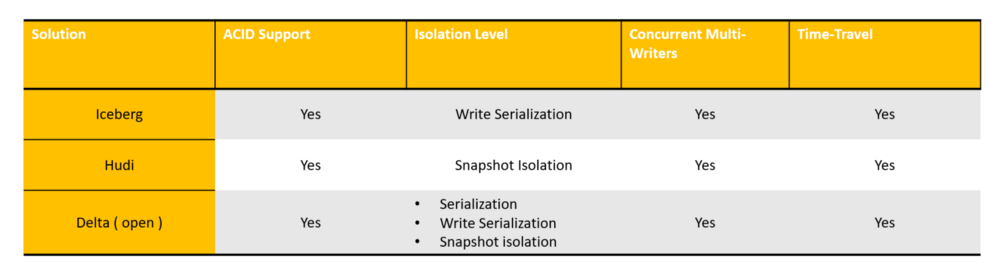
ACID and Isolation Level Support
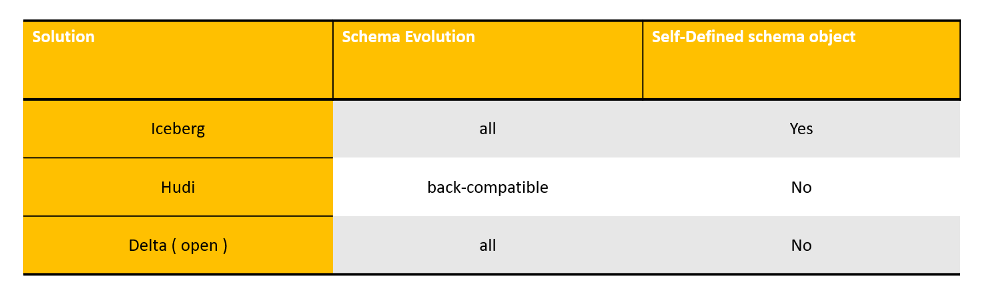
Schema Evolution
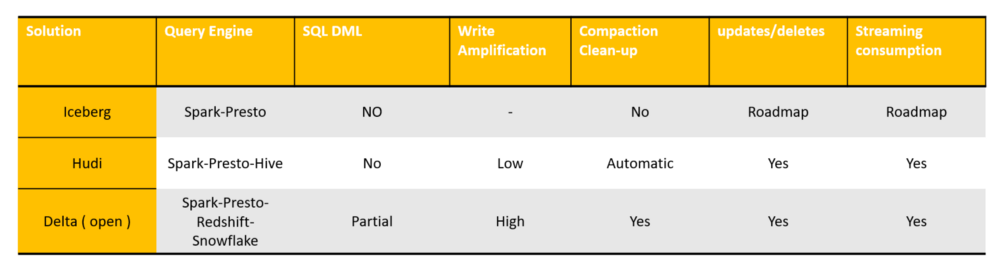
Hudi only supports the addition of optional columns and the deletion of columns. This is a backward-compatible DDL operation, while other solutions do not have this limitation. The other is whether the data lake customizes the schema interface in order to decouple from the calculation engine’s schema. Iceberg is doing a good job here, abstracting its own schema, and not binding any calculation engine-level schema.
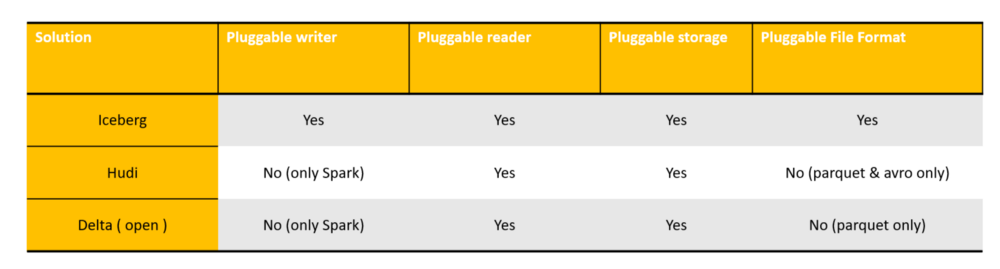
Openness
Here Iceberg is the best data lake solution with the highest degree of abstraction and flexibility, and all four aspects have done a very clean decoupling. Delta and Hudi are strongly bound to spark. Storage pluggable means whether it is convenient to migrate to other distributed file systems (such as S3), which requires the data lake to have the least semantic dependence on the file system API interface, for example, if the data lake’s ACID strongly depends on the file system rename, if the interface is atomic, it is difficult to migrate to cheap storage such as S3.
Performance
Iceberg is the only one adding features that can be leveraged by processing engines to skip files based on metadata. Delta Lake can provide advanced features like Z-Order clustering or file skipping, but only in the commercial version provided by Databricks. If they are going to release them it will be a huge step forward in performances.
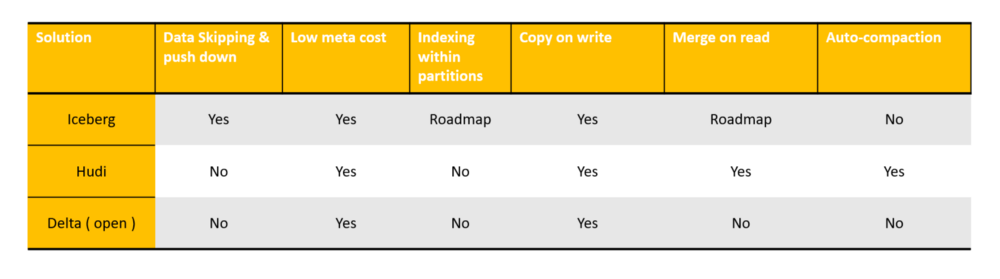
For data security considerations, Iceberg also provides file-level encryption and decryption functions, which is an important point not considered by other solutions.
Wrapping up
Iceberg’s design is very solid and open and is gaining traction.
Hudi’s situation is different, it is the eldest on the market so it has some competitive advantage (like merge on read), but it is difficult to evolve it. For example, if you are wondering to use it with Flink or Kafka streams, forget about it.
Delta has the best user API, good documentation, and good foundations. The community is totally powered by Databricks that is owning a commercial version with additional features. This could be a good point or a bad one…

CTO & Co-Founder. Paolo explores emerging technologies, evaluates new concepts, and technological solutions, leading Operations and Architectures. He has been involved in very challenging Big Data projects with top enterprise companies. He's also a software mentor at the European Innovation Academy.
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!
Is Data Mesh the future of Data Engineering? Roberto Coluccio, Data Architect at Agile Lab tries to answer the question.
An article by Paolo Platter, CTO at Agile Lab, talks about the real value of data - Dagens Infrastruktur Sweden