USE CASE
Secondary Indexing on HBase, a.k.a. NoSQL is good but not totally
Secondary Indexing on HBase, a.k.a. NoSQL is good but the world is not key-value
Darwin is a lightweight repository written in Scala that allows to maintain different versions of the Avro schemas used in your applications. It is an open-source portable library, useful for Big Data
Avro allows us to store data efficiently in size, but it is not easy to set it up in order to enable data model evolution over time.
Avro is a row-based data serialization format. Widely used in Big Data projects, it supports schema evolution in a size efficient fashion, alongside with compression, and splitting. The size reduction is achieved by not storing the schema along with the data: since the schema is not stored with each element (as it would be with a format like JSON) the serialized elements contain only the actual binary data and not their structure.
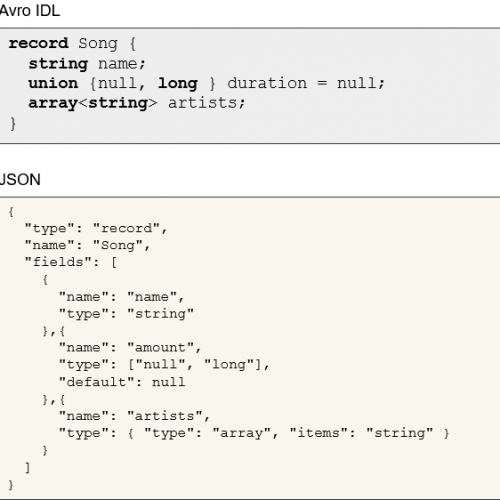
Let’s see how this is achieved by looking at an example of serialization using Avro. First of all, the schema of the data that should be serialized can be defined using a specific IDL or using JSON. Here we define the hypothetical structure of a “song” in our model with the Avro IDL and the equivalent JSON representation:
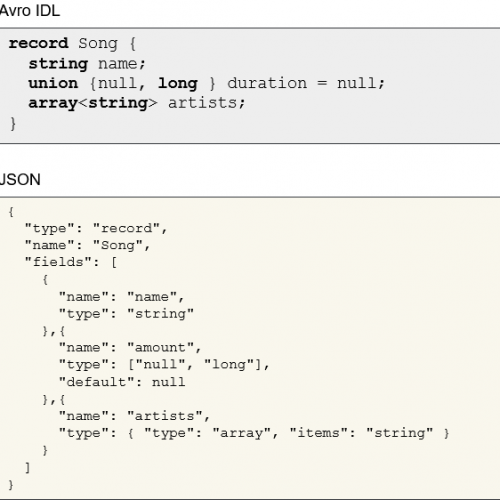
IDL and JSON schemas for Song elements
Since the schema is the same for all elements, each serialized element could contain only the actual data, and the schema will tell a reader how it should be interpreted: the decoder will go through the fields in the order they appear in the schema and will use the schema to tell the datatype of each field. In our example, the decoder could be able to decode a binary sequence like:
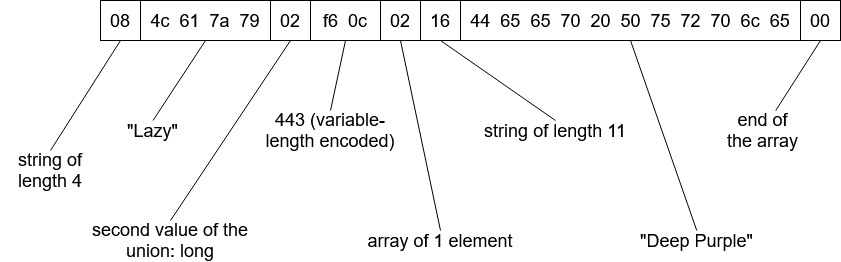
The binary values are interpreted by the decoder using the schema
One of the problems with the above implementation is that in real scenarios data evolve: new fields are introduced, old ones are removed, fields can be reordered and types can change; e.g. we could add the “album” field to our “song”, change its “duration” field from long to int and change the order of the “duration” and “artists” fields.
To ensure that we don’t lose the ability to read previously written data in the process, a decoder must be able to read both new and old “songs”. Luckily, if the evolution is compliant to certain rules (e.g. the new “album” field must have a default value), then Avro is able to read data written with a certain schema as elements compliant to the newest one, as long as both schemas are provided to the decoder. So, after we introduce the new song schema, we can tell Avro to read a binary element written with the old schema using both the old and the new one. The decoder will be automatically capable of understanding which field of the old schema is mapped to the fields of the new one.
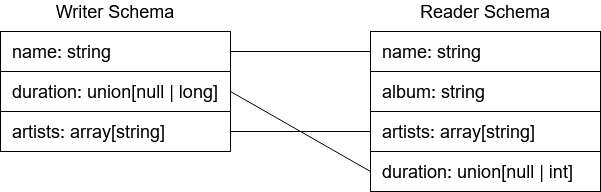
Elements written with an older version of the schema can be read with the new one performing a mapping
between the old and the new fields
Note that if the decoder is not aware of the older schema and tries to read some data written with the old schema, it would throw an error since it would read the “album” field value thinking it represents the “song” duration.
So it seems that everything works fine with Avro and schema evolution, why should I worry?
Yes, everything is managed transparently by Avro, but only as long as you provide to the decoder not only the schema your application expects to read, but also the one used to encode every single record: how can you know which schema was used to write a very old record? A solution could be to store each element along with its schema, but this way we are going back to store data and schema together (like JSON) losing all the size efficiency!
Another solution could be to write the schema only once into the header of an Avro file with multiple elements that share the same schema in order to reduce the number of schemas per element, but this is not a solution that could be always applied, and is tightly coupled to the number of elements that you can write together in a single file.
Luckily, Avro comes to the rescue again with a particular encoding format called Single-Object Encoding. With this encoding format each element is stored along with an identifier of the schema used for the serialization itself; the identifier is a fingerprint of the schema, to be meant as a hash (64 bit fingerprints are enough to avoid collisions up to a million entries).
From Avro documentation:
Single Avro objects are encoded as follows:
* A two-byte marker, C3 01, to show that the message is Avro and uses this single-record format (version 1).
* The 8-byte little-endian CRC-64-AVRO fingerprint of the object’s schema
* The Avro object encoded using Avro’s binary encoding
OK, now we don’t have the actual schema, but only a fingerprint… how can we pass the schema to the decoder if we only have its fingerprint?
Here is where Darwin comes to our help!

Darwin is a lightweight repository written in Scala that allows to maintain different versions of the Avro schemas used in your applications: it is an open-source portable library that does not require any application server!
To store all the data relative to your schemas, you can choose from multiple storage managers (HBase, MongoDB, etc) easily pluggable.
Darwin keeps all the schemas used to write elements stored together with their fingerprints: this way, each time a decoder tries to read an element knowing only the reader schema, it can simply ask Darwin to get the writer schema given its fingerprint.
To plug a Connector for a specific storage, simply include the desired connector among the dependencies of your project. Darwin loads automatically all the Connectors it finds in its classpath: if multiple Connectors are found the first one found is used or you can specify which one to use via configuration.
Even if it is not required when used as a library, Darwin provides a web service that can be queried using REST APIs to retrieve a schema by its fingerprint and to register new schemas. By the time this article is written, Darwin provides connectors for HBase, MongoDB and a REST one that can be linked to a running instance of the Darwin REST server.
Each Connector requires its own set of configurations, e.g. for the HBaseConnector:
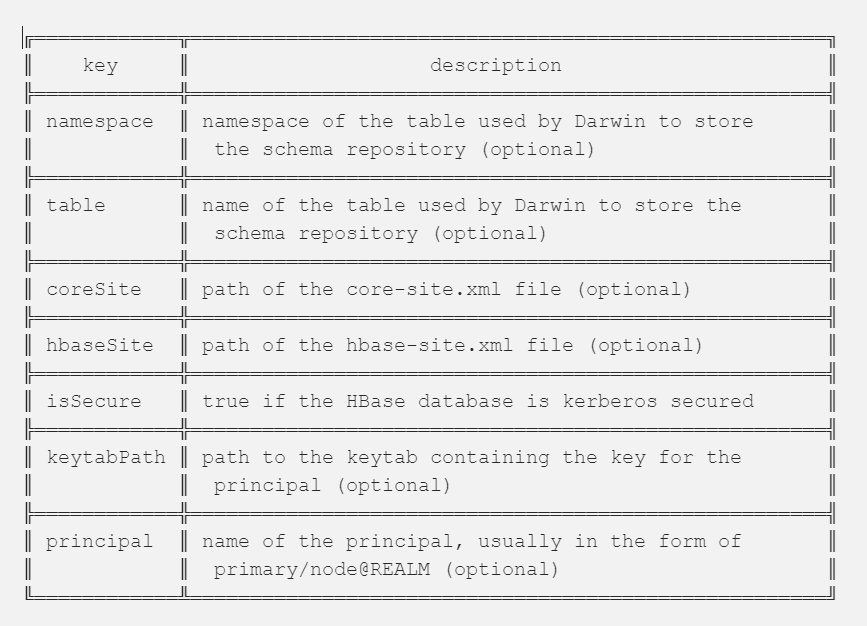
Darwin can be configured to run in three different modes:
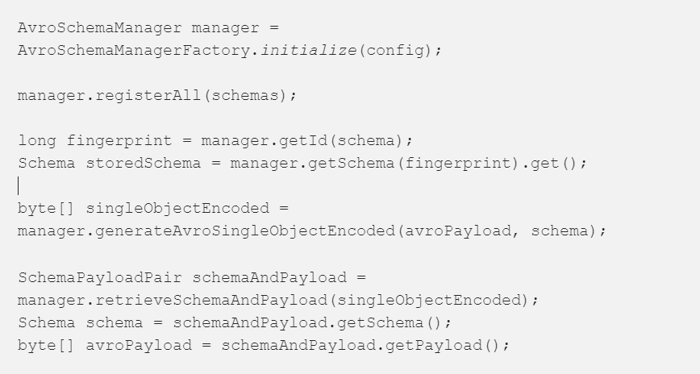
Using Darwin is very easy! Here we have a Scala simple example: first of all we must obtain an instance of AvroSchemaManager passing the desired configurations

Then every application can register the Avro schemas needed by simply invoking

The AvroSchemaManager can then be used to retrieve a schema given its fingerprint and vice-versa

Since the data will be stored and retrieved as single-object encoded, Darwin exposes also APIs to create a single-object encoded byte array starting from an Avro encoded byte array and its schema:
It also provides APIs to retrieve schema and Avro encoded byte array from a single-object encoded element:

The same code in Java would be:
In Agile Lab we use Avro in different projects as a serialization system that allows us to store data in a binary, fast, and compact data format. Avro achieves very small serialization sizes of the records by storing them without their schema.
Since data evolves (and their schemas accordingly), in order to read records written with different schemas each decoder must know all the schemas used to write records throughout the history of your application. This will cause each application that needs to read the data to worry about the schemas: where to store them, how to fetch them and how to tell which schema was associated to each record.
To overcome said evolution problems in our projects, we created Darwin!
Darwin is a schema repository and utility library that simplifies the whole process of Avro encoding/decoding with schema evolution. We are currently using Darwin in multiple Big Data projects in production at Terabyte scale to solve Avro data evolution problems.
Darwin is available on Maven Central and it is fully open source: code and documentation are available on GitHub.
So give it a try and feel free to give us feedback and contribute to the project!
Senior Big Data Engineer. He started his career as a full stack engineer and then moved to big data. Lately he has been focusing on the creation of Witboost, as project leader and architect, managing highly complex environments, and acting as an experienced technical team leader.
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!
Secondary Indexing on HBase, a.k.a. NoSQL is good but the world is not key-value
Agile Lab explore with Neodata Group Elasticsearch and some interesting use cases on data analysis
Apache Spark is the most widely used in-memory parallel distributed processing framework in the field of Big Data advanced analytics.