
For the most part, frameworks provide all kinds of built-in functions, but it would be cool to have the chance to extend their functionalities transparently.
In particular, in this article, I want to show you how we solved an issue that emerged while working with Flink: how to add some custom logic to the built-in functions already available in the framework in a transparent way. I will present our solution with a simple example: adding a log that tells how long each element took to be published by a sink, but this solution can be extended to add your custom logic to any Flink component.
In this article, after a short introduction to Flink, I will analyze a little bit more its functions (sinks in particular): the interfaces provided by Flink, the methods they expose, how they are implemented, and a basic interface hierarchy. Then I will proceed to show you how regular solutions (extending the basic interfaces or wrapping them) are not enough to solve the problem. In the end, I am going to show you the actual solution using Java dynamic proxy, which will allow us to extend the functions by adding our custom code. Finally, the last paragraph will try to explain why our solution could be improved even more by handling the Object methods in a specific way: this will allow us to make our dynamic proxy with custom logic completely indistinguishable from the function it enriches.
Flink in a nutshell
Flink is an engine capable of processing efficiently streaming events supporting out-of-the-box time and state handling as well as fault tolerance and metrics extraction. Quoting the official Flink documentation:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
As reported in the documentation, data can be processed as unbounded or bounded streams:
- Bounded streams have a defined start and end. When processing bounded streams you have full control over data since you already know all of it. This allows you to ingest all elements before performing any computation on them (e.g. you can perform a consistent sort of all the events before processing them). Whenever a bounded stream is elaborated we talk about “batch processing”.
- Unbounded streams have a known start but no defined end. They are an actual flow of elements continually generated (so they should be continually processed as they arrive). It is not possible to reason about the whole data set since it is continually generated (we cannot sort the input elements), but we can only reason about the time at which each event occurred. The elaboration of unbounded streams is known as “stream processing”.
Even if Apache Flink excels at processing both unbounded and bounded data sets, we will focus on the feature for which it is best known: stream processing. A detailed time and state management enable Flink’s runtime to run different kinds of applications on unbounded streams.
Flink applications rely on the concept of streaming dataflow: each streaming dataflow is a directed graph composed of one or more operators. Each operator receives its input events from one or more sources and sends its output elements to one or more sinks. Flink provides a lot of already defined sources and sinks for the most common external storages (message queues such as Kafka or Kinesis but also other endpoints like JDBC or HDFS) while operators are usually user-defined since they contain all the business logic.
It is very simple to define a streaming flow in Flink: given a Flink environment simply add a source to it, transform the data stream with your logic and publish the results by adding a sink to it:

The data stream code is mapped to a direct logical graph and then executed by the framework. Usually, when the user defines its transformation they will be mapped to a single operator in the dataflow, but sometimes complex transformations may consist of multiple operators.
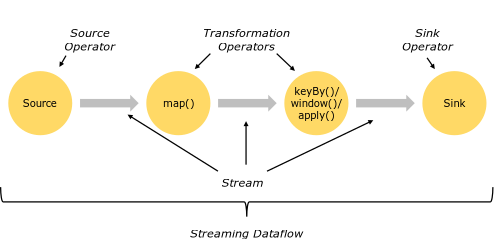
Flink logic dataflow (image from the official documentation)
All Flink streams are parallel and distributed: each stream is partitioned and each logical operator is mapped to one or more physical operator subtasks. Each operator has associated parallelism that tells Flink how many subtasks it will require (in the same stream different operators can have different parallelisms); each subtask is decoupled from all the others and is executed in a different thread (and maybe on different nodes of the cluster).
Meet the Flink functions
Let’s focus now on how the single components are defined inside Flink using the sink as an example:

The invoke() method is invoked for each input element, and each sink implementation will handle it by publishing it to the chosen destination.
Since some sinks require additional functionalities to grant data consistency and/or state management, Flink defines extensions of the SinkFunction interface that include other utility methods. The first example could be the abstract class RichSinkFunction that extends not only SinkFunction but also AbstractRichFunction to include initialization, tear-down, and context management functionalities:

Each concrete sink will implement only the sink interface they need to perform their logic, some examples could be:
- DiscardingSink, which is an implementation that will ignore all the input elements, extends only SinkFunction since it does not require state management either initialization;
- PrintSinkFunction, which writes all the input elements to standard output/error, extends RichSinkFunction because it will initialize its internal writer in the open() method using the runtime context;
- FlinkKafkaProducer, the official Kafka sink, extends TwoPhaseCommitSinkFunction because it requires some additional functionalities to handle checkpoints and transactions.
Even if they differ in behavior, all these implementations, and other functions that add other functionalities, extend the base interface SinkFunction. Given this structure of the sinks (that is similar for sources and operators too), we can now take a step further to analyze how we can add functionalities to an existing sink.
One does not simply wrap a Flink function
Let’s say that we want to define a mechanism capable of adding some functionalities to our sinks; as a general example, we’ll discuss how we can add a log before and after each element processing to highlight how long each element took to be published.
Obviously one could extend each existing sink with a custom class overriding the default behavior; this approach is not sustainable since we would encounter multiple problems: we would define various classes all with the same code replicated, we would need to keep this set of extensions updated at each new implementation released, and we would be stuck in case the implementation overrides the abstract method we need to extend with the final keyword.
So a more reliable first approach would be to define a wrapper around the sink (the wrapper would implement SinkFunction itself) and redirect its invoke method to the inner sink after applying the additional logics:

Now we can add our wrapper to any data stream and it will transparently perform the publishing defined inside the inner sink along with our custom logic:

The problem with this approach is that if we use our SinkWrapper we lose the actual specific interface implemented by the inner sink: e.g. even if the inner sink is a RichSinkFunction, our wrapper would be a simple SinkFunction. This should not be an issue, since as shown above the signature of the addSink() method of DataStream takes a SinkFunction:

Actually, it happens that this is a problem because even if there are no compilation errors, Flink handles differently the various kinds of SinkFunction by checking their type at runtime. In fact, if you take a look at the Flink classes FunctionUtils or StreamingFunctionUtils, you will notice how their methods check the actual type of the function to invoke specific methods on it, e.g.:

So our wrapper solution cannot work for all the sinks that are not only SinkFunction but extend other interfaces too (which are the vast majority of the sinks). Our wrapper would need to implement also these interfaces and redirect all the abstract methods to the wrapped element, but in this way, we are back to a similar problem of defining a specific class for each implementation!
It is dangerous to go alone, take a Java dynamic proxy
The Java dynamic proxy mechanism (available in the standard Java JDK) allows one class to act as a facade for multiple method calls to arbitrary classes. The interesting part is that the proxy itself can pretend to be an implementation of any interface. To achieve this, the proxy routes all method invocations to a handler that will handle the various method invocation through its invoke() method.
An invocation handler is simply an instance responsible for defining a logic associated with the invoke() method: this method will be invoked for all the methods that the proxy exposes. The invoke() method of the handler will be called with three parameters: the proxy object itself (we can ignore it), the method invoked on the proxy and the parameters passed to that method.
As a first example we can define a simple generic InvocationHandler that logs how many times a method was invoked:

Note that in this example the method invoked on the proxy will only log the number of times the method was invoked without doing anything else!
Now that we have a handler we can define an actual proxy that implements the desired interfaces:

As shown in the snippet the proxy creation requires three parameters:
- the class loader to define the proxy class
- the list of interfaces for the proxy class to implement
- the invocation handler to dispatch method invocations to
The advantage of this solution is that the resulting proxy implements all the interfaces that we chose while adding the logic of the handler to all methods invocations.
Almost there, just another step
Now that we introduced the dynamic proxy we can use it to solve our sink extension problem: we can define a wrapper for our sink that adds our logic that implements the same interfaces as the wrapped sink!
First of all, we define our wrapper that will contain an existing sink:

Then we need to define an InvocationHandler that contains our logic, and to keep the solution simple the wrapper itself can implement it:

For the moment we can leave the invoke method unimplemented, we are going back to it soon, and let’s focus on the creation of our dynamic proxy. Since we want the users to use our wrapper class transparently, we can make the constructor private and provide a static utility method that will wrap the sink directly with the proxy:
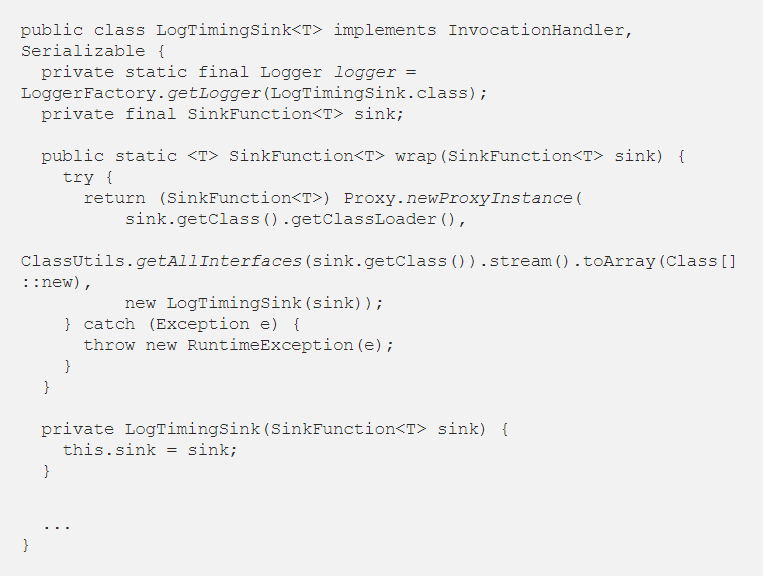
Notice that the wrap() method will be the only access point to our wrapper, and it will always return the dynamic proxy built on top of our wrapper. The ClassUtils.getAllInterfaces() method, which returns all the interfaces implemented by a class, is defined inside Apache’s commons-lang3 which is imported as a dependency by Flink itself.
So whenever a sink is wrapped using the wrap() method, the resulting sink will implement all the interfaces of the original sink but all the methods invoked on it will pass through our handler. Now we can implement the invoke() method to add our logic to the wrapped sink.
Since we need to add our custom logic only to the sink invoke() method, we need to check which method was called: if it is the sink invoke() method we add our logic around the invocation (e.g. logging how much the method took to process the input element) while if it is another one we can invoke it directly on the wrapped sink:
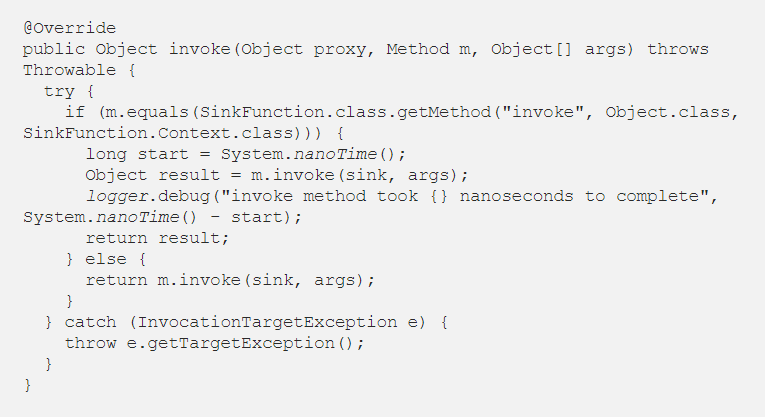
Pretty simple, right? We check if the method intercepted is the SinkFunction invoke() and then we add our logic before and/or after calling it on the wrapped sink. For all the other methods, they are invoked directly on the inner sink.
Our wrapper is ready and we can use it in our data stream by simply wrapping our sink:

And Another Thing…
Cool! But we can slightly improve our wrapper if we think about what our proxy stands for: when we wrap our sink we are given a proxy that we can actually substitute transparently to our original sink since it implements all its interfaces and will invoke all its methods.
This would be true for all methods apart from the Java “Object methods”: equals(), hashCode(), and toString(); we need to handle these Object methods with specific logics since they are invoked on the proxy and not on the wrapped sink, so we could have inconsistencies if we use the proxy instead of the wrapped element. To solve this issue we can:
- handle the equals() method to check if the compared object is a proxy too: in this case, we can compare the two inner sinks. If it is not a proxy we can call the underlying equals method directly, avoiding using reflection.
- redirect the hashCode() and toString() methods directly onto the wrapped sink.

The interesting part of the solution presented is that we can also handle operations specific to particular kinds of sinks since we implement all their interfaces. As an example, in our InvocationHandler we could intercept also the open() and close() methods of RichSinkFunction, knowing that these methods will be invoked only if the wrapped sink is a RichSinkFunction.
If you made it this far, you may be interested in other Big Data articles that you can find on our Knowledge Base page. Stay tuned because new articles are coming!
Written by Lorenzo Pirazzini – Agile Lab Big Data Engineer
Remember to follow us on our social channels and on our Medium Publication, Agile Lab Engineering.
