Data Platform
Data Catalogs: The Foundation of Data Platform Success — Part 1
Discover data catalogs' critical role in successful data platform initiatives, in this first part of the series.
In a previous post, we presented our research project, Data Platform Shaper (DPS), which we used as a laboratory to investigate new ideas around flexible metadata catalogs. We tried to make DPS as flexible and expressive as possible during our investigation. A sound data platform design process that aims to introduce good engineering practices drives DPS development; this process could be quickly summarized in the following phases, as outlined in the previous post:
This post shows a new DPS feature that allows us to better adhere to the above process.
Let’s suppose we want to build a data mesh so that after the process phases above, we would come up with the following overall model:
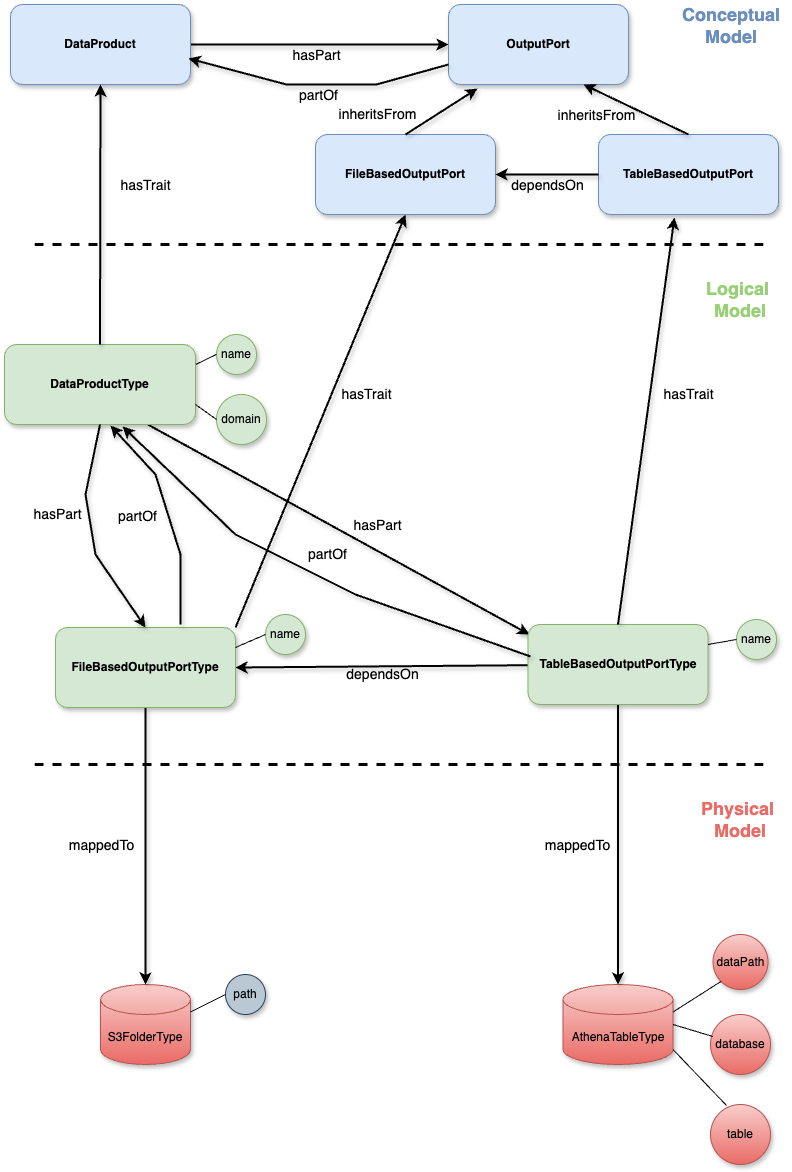
The figure above is a pictorial representation of a data mesh across different models.
The conceptual model defines the kind of assets a data mesh contains and their possible relationships. So, in the figure, the conceptual model includes the following assets:
In DPS, the conceptual model can be expressed in terms of traits and their relationships. So, we can create a corresponding trait for each asset above.
Once the assets/traits are defined, we must determine their relationships.
A DataProduct has a hasPart (with its opposite partOf) relationship with OutputPort, which models that a data product contains a list of output ports.
A TableBasedOutputPort has a dependsOn relationship with a FileBasedOutputPort. This relationship models the typical situation where the computational layer, i.e., a SQL engine, is separated from the storage layer, i.e., object storage. In this context, we model it in such a way that a table is mapped on top of a collection of stored files using a specialized SQL engine.
Now, we can move to the logical model. We must define the actual types with their attributes, making the abstract concept described in the conceptual model concrete.
In DPS, the logical model is defined in terms of types associated with specific traits to determine their nature and behavior.
In this case, it’s pretty simple; we define the following types:
In DPS, the relationships are automatically inherited from the traits, so we don’t need to define them explicitly in the logical model.
Once we define the logical model, we need to determine the physical model. The physical model represents how the data platform assets are implemented with a specific technology. In DPS, we defined a special relationship mappedTo to describe this mapping type.
For example, a FileBasedOutputPortType needs a place to store its files, so if the target technology is AWS, we could define a type S3FolderType with an attribute path and associate the FileBasedOutputPortType with S3FolderType with the special relationship mappedTo.
Similarly, a TableBasedOutputPortType needs an SQL engine capable of creating a table on top of stored files; in the AWS ecosystem, we could choose Athena and create a specific type AthenaTableType with three attributes: dataPath, database, and table. Then, we can map TableBasedOutputPortType to AthenaTableType with the mappedTo relationship.
In DPS, the mappedTo relationship is associated with the mapping feature. First of all, the mappedTo relationship is a ternary relationship with the following structure:
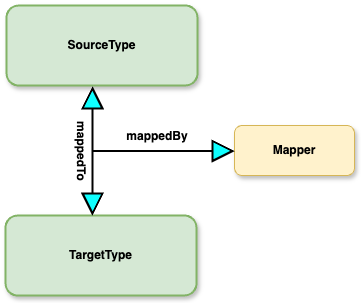
A SourceType is mapped to a TargetType, which means that every time we create an instance of the SourceType, an instance of TargetType is automatically created and linked to the source instance by a mappedTo relationship.
The mapper is a particular instance of the TargetType where its attributes contain expressions used by DPS to compute the attribute values of the target instance. During the mapping evaluation, DPS injects a reference of the source instance into the expression engine, so it’s possible to define the mapper expressions in terms of the values of the source instance attributes. Additionally, DPS is also able to inject any reference to instances that can be reached from the source instance. In this way, it’s also possible to compute attribute values, taking into account the surrounding instances.
In our example, the mapper associated with the mappedTo relationship between FileBasedOutputPortType and S3FolderType contains only one expression attribute:
path: “dataproduct.get(‘domain’) += ‘/’ += dataproduct.get(‘name’)”
In the expression above, dataproduct is an alias for the instance of DataProductType that can be reached through this path:
source/partOf/DataProductType
where source is the source instance in the mapping (an instance of FileBasedOutputPortType). This expression simply computes the folder path as <dataproduct_domain>/<data_product_name>.
The other mapper associated with the mappedTo relationship between TableBasedOutputPortType and AthenaTableType contains three expression attributes:
table: “source.get(‘name’)”
The table name is simply the name of the TableBasedOutputPortType.
database: “dataproduct.get(‘domain’) += ‘.’ += dataproduct.get(‘name’)”
The database name is defined as <dataproduct_domain>.<data_product_name>.
dataPath: “s3folder.get(‘path’) += ‘/’ += ‘outputport’ += ‘/’ += source.get(‘name’)”
The data path, where the table files are stored, is defined as <s3_folder_path>/outputport/<outputport_name>. Where s3folder is an alias for the instance at the path:
source/dependsOn/FileBasedOutputPortType/mappedTo/S3FolderType
That path shows the usage of the dependsOn relationship. In our example, an instance of TableBasedOutputPortType depends on an instance of FileBasedOutputPortType since its attributes can only be derived from the attribute values the instance depends on.
The full example, particularly the file DataPlatformShape.yaml, contains all the DPS definitions for creating the model above, and it can be found in the project directory https://github.com/agile-lab-dev/data-platform-shaper/tree/main/examples/datamesh/simple.
Data Platform Shaper has been a fantastic project in which we had the opportunity to experiment with new ideas. Most of those ideas have been gradually incorporated into my company's flagship product, Witboost.
We got excellent feedback from the scientific community with our paper and from the Witboost development team; for us, this is an essential confirmation that a modern data platform can be effectively managed only by adopting a flexible metadata catalog capable of modeling the complexity of all the assets it’s based upon.
Discover data catalogs' critical role in successful data platform initiatives, in this first part of the series.
Unlock productivity & reduce cognitive load for data engineers with platform engineering. Streamline processes, enforce best practices, & automate...
Discover how platform engineering enhances software development by integrating technologies, standardizing workflows, and focusing on user-centric...