LLM
Shadow AI: Governing the invisible
Learn how to balance innovative AI tool usage with essential security and compliance measures to protect your organization from hidden risks.
This contribution wants to shed a light on some of the limits that a Data Mesh implementation will experience sooner or later.
Actually, the same reasoning can be applied to any enterprise initiative where the organization, platform, and culture need to find a balance.

Big enterprises are the realities most exposed to the benefits of Data Mesh. This paradigm has an important organizational impact and can sort and control a certain amount of unexpected complexity.
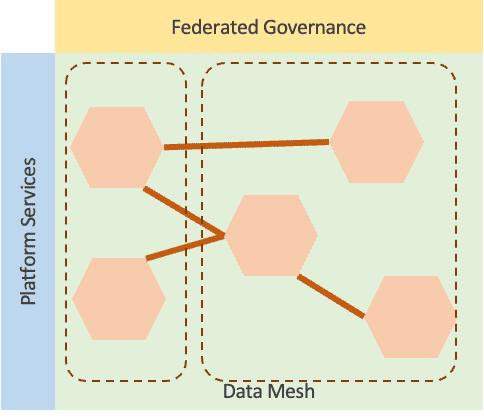
In this article, I refer to an implementation of the Data Mesh paradigm as an ensemble of domains, a self-service platform (and its team), federated governance, and a population of data products, implying cultural initiatives, incentive policies, automated and human processes, decision-making practices, and organization that support the functioning of the Data Mesh.
Data Mesh implementations have their own limits they must deal with. This section elaborates on those limits and provides a framework to take a strategic decision for such an initiative. It is important to have them outlined to avoid unexpected surprises. Having the whole landscape of constraints should make it possible to detect some limits in advance and either design beyond those limits or work them around.
The designed cloud infrastructure to build a Data Mesh platform is a function of the number of several kinds of resources.
A resource is any infrastructural element that enables a cloud service. Roles, APIs, clusters, storage, etc. can be consumed up to virtual and physical limits at a certain speed depending on how the data mesh platform is designed.
Of course, applying the principle of continuous refactoring to the infrastructure is key to chasing new challenges. Anyhow, any new solution will have critical resource limits that I am going to identify as the infrastructure breakpoint. Beyond that boundary, the self-served platform cannot be used because of a lack of resources.
As an architectural quantum, the data product is likely to consume an almost fixed portion of infrastructure items. We can suppose that a platform will grow linearly with the number N of data products.
There is the option where the data mesh platform is not actually tied to a single infrastructure backbone to run data products. For instance, we run workloads and output ports on several data platforms governed by a single data mesh platform. They can still communicate because output ports are standards, discoverable and addressable but their infrastructure runs on platforms that have their own limits. In this case, the same reasoning applies at the minimum of those limits.
Coordination breakpoint. The federated governance establishes the need for collaboration among domains, SMEs, and the platform team. Federated governance requires decision-making processes to set up policies, evolutions, and conditions for the Data Mesh to work.
Nevertheless, any decision-making process does not scale well with the number of participants and in general meetings and coordination can reach a point where it is difficult — if not impossible- to take a decision.
As a known example, the same limitations apply to agile teams working to build a data product. Agile methodologies have several approaches. Whether they suggest 3-to-9 people or exactly 7 members per team, none of them declares 100 members working within the same agile team. After a certain small number of participants, scaled agile methodologies prevail.
We can call this limit the coordination breakpoint.
Capacity breakpoint. The number of participants can be limited by the total number of resources available within a department, area, or company. A limited number of human resources requires sharing this workforce among different needs. This may be a limited number of resources within a domain with a growing number of data products or a group of different domains represented by a single member of the federated governance.
Let’s mark this as the capacity breakpoint.
In any case, there is a cognitive limit to the amount of work that a person or organizational unit can deliver at a certain quality, time, and cost beyond which there is degradation or impossibility to proceed. Limits due to coordination complexity and capacity can be considered a cognitive breakpoint.
Regional regulations, industry standards, auditing requirements, and other constraints can affect the implementation of the Data Mesh paradigm. In that case a split by legal entities or other criteria that partition by data sovereignty criteria the company organization must be taken into account as a limit to work around.
We can call this a data sovereignty breakpoint.
We can place our Data Mesh implementation in a multidimensional space where each dimension represents a constraint. Setting the upper limits (red markers) defines within which surface we can comfortably work with our Data Mesh implementation. We can define it as the region of sustainable growth.
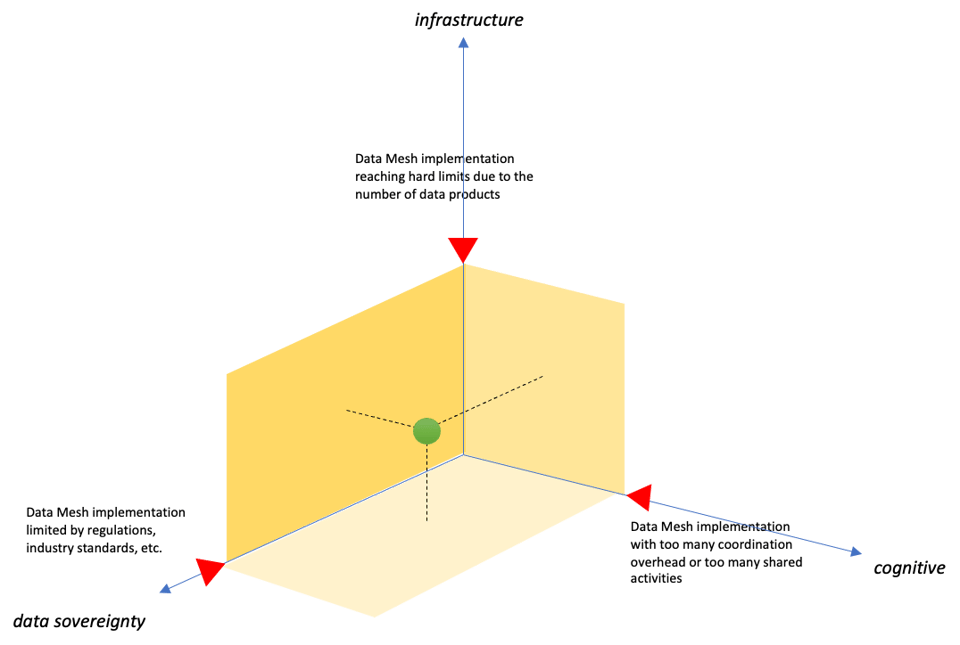
Moving beyond any of the breakpoints determines the necessity to scale out the Data Mesh implementation (or any comparable effort).
Given our framework to assess the boundaries of our Data Mesh implementation, it is time to discuss how to move beyond those limits.
A Data Mesh implementation able to support the business objectives stays within the constraints in the region of sustainable growth. This implies that the ensemble of domains, the self-service platform, the federated governance, and the population of data products are in good reciprocal balance.
If the infrastructure breakpoint is reached because of the unsustainable growth of the population of data products, it is necessary to exceed the current limits.
This makes sense for the Platform as a Product attitude to move to a Platform product reality. Building a platform on automated infrastructure and a strict API-first approach enables horizontal scaling of the platform product.
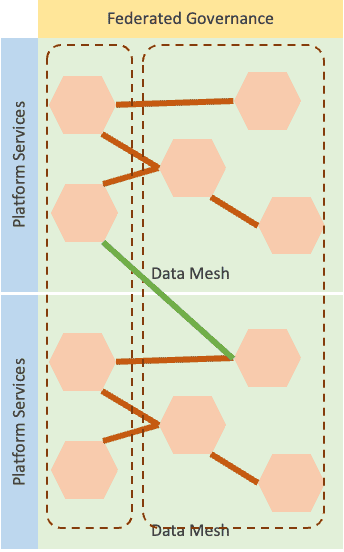
The self-serve platform must be able to stretch domains across multiple platforms and open routes among platform instances. Consolidation and automation around federated catalogs and interconnected platforms can represent a further enhancement of a single platform architecture in the case the rate of growth of the data product population is very high.
In the case of a cognitive breakpoint, there is a need for scaling out the organization. The platform development team shall account for requirements from all the domain clients of the platform. Data Mesh implementation would require domain stakeholders to participate in the federated governance. For instance, if there are too many domains, scaled agile methodologies (or similar approaches to scale out organizations) could apply.
In this case, a single platform instance of Data Mesh implementation keeps hosting the whole population of data products.
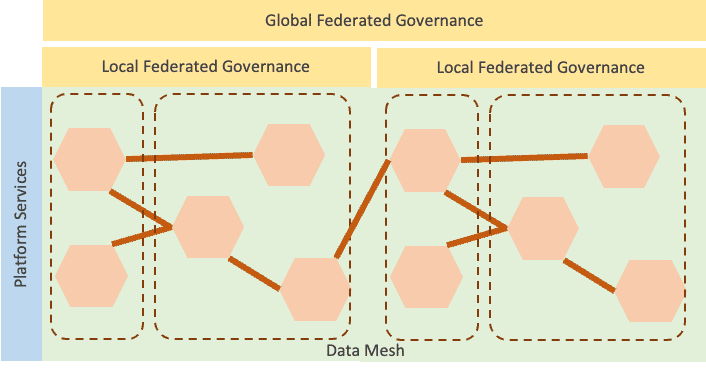
The cognitive breakpoint affects coordination also in the case of the platform team. To alleviate the capacity issue, the organization shall account for extending the team. The more populated the team is, the more coordination is necessary which pushes coordination overhead. This is where scaled agile methodologies help as well.
A Data Mesh implementation can scale in the direction of data sovereignty by enabling — for instance — multitenancy. This platform's capability is neither trivial nor obvious to obtain.
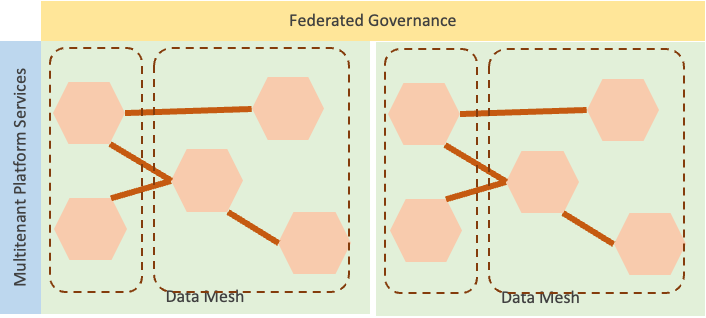
An alternative is to fall back to a solution based on federated platforms.
Whether to go one way or the other depends on the specific case, platform capabilities, federation mechanisms, etc. I would not underestimate how to scale out over legal entities since this may require features not easy to embed in the existing Data Mesh implementation.
As the complexity of the organization grows, the trajectory towards a data sovereignty breakpoint can touch cognitive breakpoints as well.
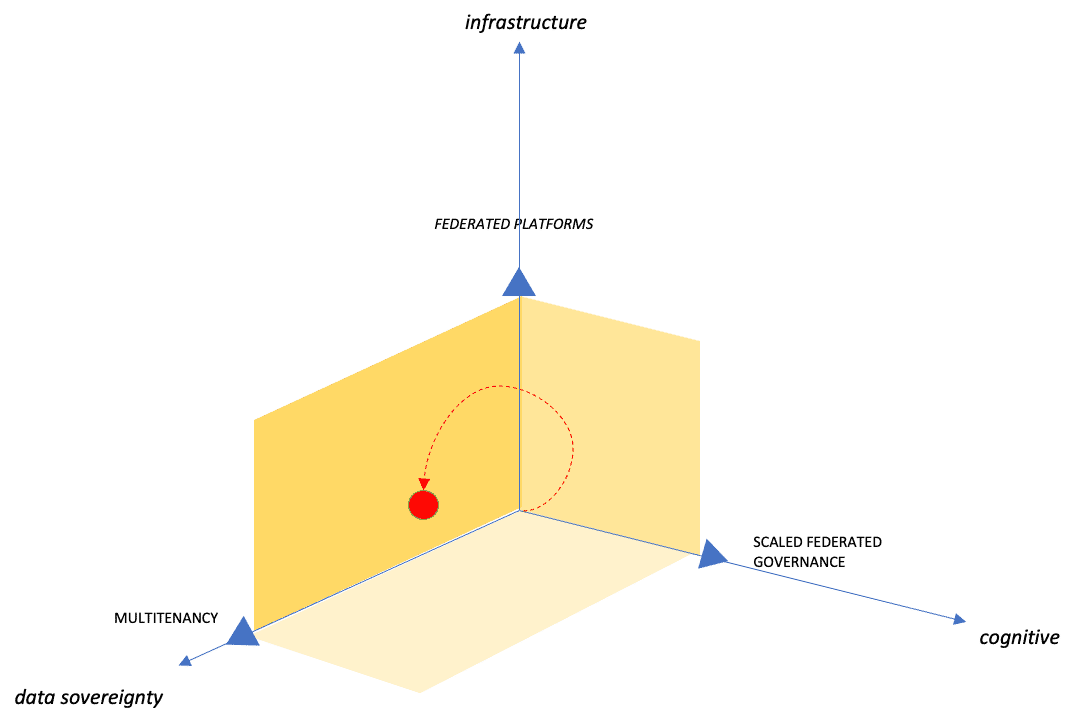
This means that the more complex an organization, the more necessary a scaled data mesh approach.
This article shows the critical breakpoints of Data Mesh implementation and how to go beyond those limits. Think for instance about the organizational complexity and variety of domains in the pharmaceutical industry or in food & beverages. The same scale applies to deregulated markets such as energy and utilities. A strong diversification strategy is another symptom of great complexity that is likely to reach breakpoints very soon.
As we have seen, the scaled data mesh approach applies to very big enterprises. In these cases, there are three major takeaways:
Business Unit Leader of Utilities. Ugo leads high-performing engineering teams and has a track record of successful digital transformation, DevOps and Big Data projects. He believes in servant and gentle leadership and cultivates architecture, organization, methodologies and agile practices.
Ready to implement? Download our white paper on the Practical Guide to Successful Data Mesh Implementations!

Learn how to balance innovative AI tool usage with essential security and compliance measures to protect your organization from hidden risks.
Discover the evolution of literate programming through a new spin on code documentation, tools, and implementation in this insightful blog post.
Learn how to build a Spark Connect client with a console-based tool in Ruby, step-by-step.