spark
Build your own Spark frontends with Spark Connect Part 1: The CLI tool
Learn how to build a Spark Connect client with a console-based tool in Ruby, step-by-step.

In this article, I’ll show you how to replicate a cloud-based or on-premise infrastructure locally using Docker, Dremio, LocalStack, and Spark. Whether you’re debugging complex configurations or experimenting with new features, this hands-on tutorial provides everything you need to get started.
Shopping list:
To start, we’ll create a Docker composition that includes both a Dremio instance and LocalStack. This setup will allow us to emulate a local environment similar to our cloud setup, making testing and experimentation easy and safe.
Here’s a reference docker-compose.yml file you can use:
As you can see, the docker-compose.yml file is divided into two main blocks: dremio and localstack.
Once you have your docker-compose.yml file set up, it’s time to launch the environment.
Run the following command to start the Docker composition:
This will spin up both the Dremio and LocalStack instances. Once the services are up, navigate to http://localhost:9047 in your browser to access your fresh local installation of Dremio.
With Dremio and LocalStack up and running, let’s jump into connecting and configuring them to emulate a production-like environment. I’m sharing my findings here, but feel free to experiment with different configurations — these should provide a solid starting point!
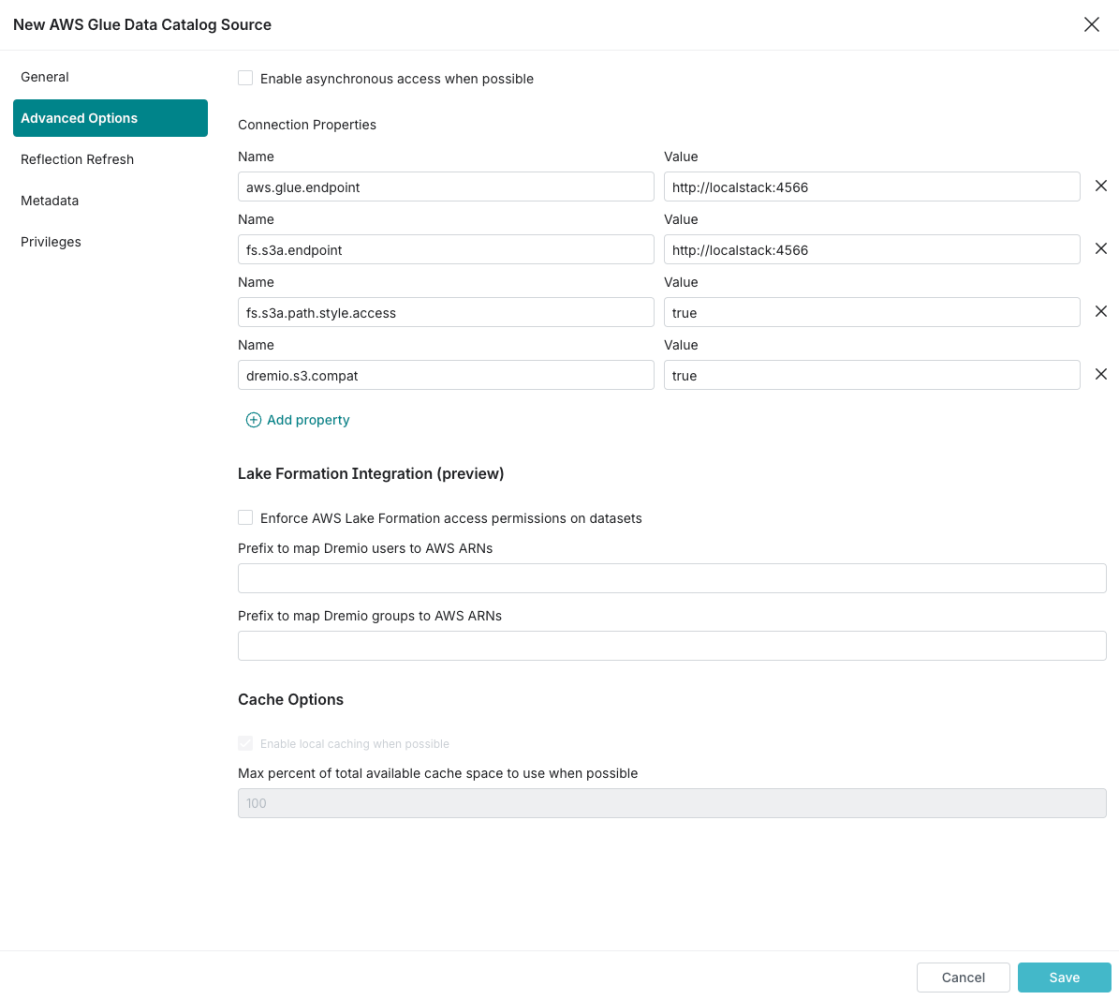
Click Save and we will have a fresh new — but still empty — source in Dremio 🚀
Now, let’s populate our Dremio Source with Parquet and Delta tables.
Let’s start with the Parquet one. Open a spark-shell on your machine and write a table:
In your Spark shell, define some sample data and schema:
🔍 Here, we’re writing the data into the data/parquet directory, which is mapped to the LocalStack volume in docker-compose.yml.
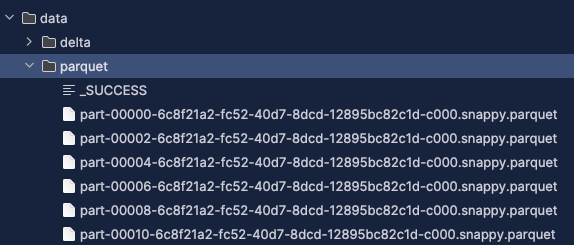
Let’s log into our LocalStack instance and create the metatable/Glue Table.
This creates a Glue table called “parquet”, with the S3 location set to s3://parquet/. But it still does not exist! Let’s create it and upload the Parquet data:
Let’s go back to Dremio and update the source. After refreshing it, you should see the newly created Parquet table under the configured Glue catalog — all running in your local environment!
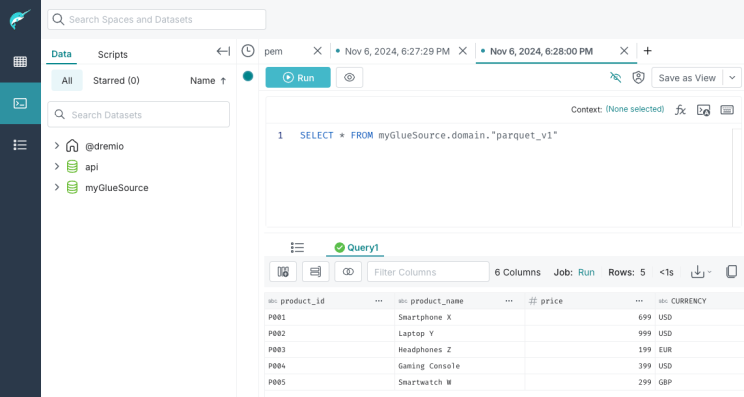
We can replicate the process for Delta Lake tables with just one minor difference: Dremio requires a Native Delta Table written in Glue. To achieve this, we need to write the Delta table in a specific way, ensuring it’s compatible with Glue metastore. More about this here and here.
🔥 Let’s fire up Spark again and create a Delta Table with Spark first.
So we get our Delta Table.
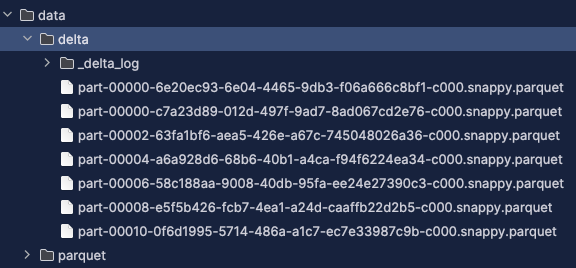
Now, let’s create the Glue table (which is going to be a Native Delta Table)
Again, this will create a Glue table called “delta”, with the S3 location set to s3://delta/. In addition, there is a schema written directly by Spark which makes the delta table native.
Let’s run a query in Dremio on our delta table!
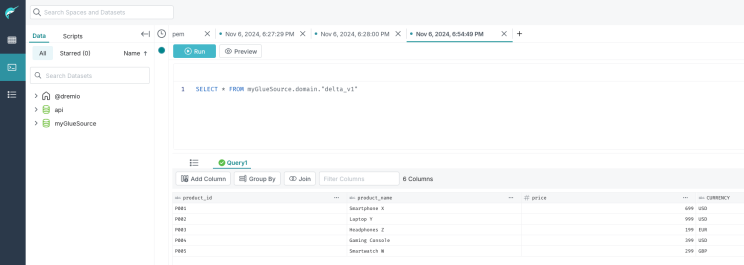
With this setup, you can test your Dremio’s interactions with Glue locally. Experiment with additional configurations or use this setup as a base for cloud deployment.
Technical note: As you may have noticed, we didn’t write a native Delta table in Glue through Spark in this current setup. This is because we’re not using Glue as the catalog for our local Spark instance. I’m actively working on incorporating Glue as the catalog for local Spark in upcoming developments 🧑💻
Learn how to build a Spark Connect client with a console-based tool in Ruby, step-by-step.
Learn how to build AI agents that provide conversational data analytics for enterprises, focusing on architecture, deployment, and LLM selection.
Explore a practical FinOps architecture for data products, focusing on cost control, ownership principles, and effective cost attribution models