FinOps
The Role of Training in Successful FinOps Adoption
Learn the critical role of training in successful FinOps adoption, fostering collaboration, enhancing cost-efficiency, and maximizing cloud ROI.
This article wants to provide a practical reference architecture to manage costs for data management platforms based on the concept of data products.
FinOps is a discipline to control, monitor and regulate cost consumption in the cloud. The holistic vision of this paradigm is particularly complex to materialise in practice although the market starts responding to the need for cost management with more or less mature tools. As usual, practices go over technology, thus having tools does not help so much in building a foundation for cost management for a data platform.
That’s why I am committed to analyzing FinOps in the analytical plane to provide effective guidance for data platform architecture design.
A platform is a tool(kit) that solves a class of problems through the minimum effort for a class of users.
In the data space, an Enterprise Data Platform implements a data management paradigm like DWH, Data Mesh, Lakehouse, etc.
Those paradigms resolve a class of similar problems providing capabilities to deploy elements like star schemas, data products, data sets, etc.
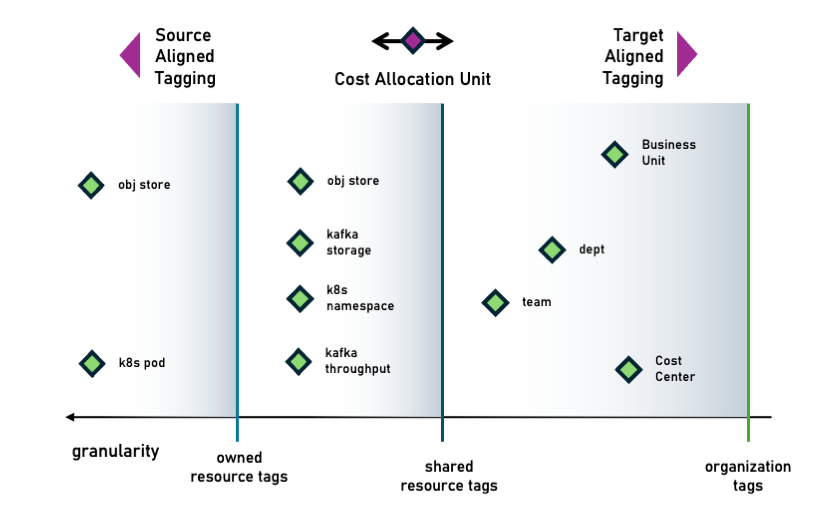
Those elements are the minimum deployable unit (architecture quantum) that can be composed to serve a use case. Data modeling plays a crucial role in reusability in any of those cases.
Although the cost of an architecture quantum should be uniquely attributed to an owner, that is not always the case. In the context of FinOps, let’s name Cost Allocation Unit the minimum set of cloud resources whose cloud spending must be assigned to an owner. This set is not necessarily bounded by an architecture quantum.
The Bounded Ownership Design Principle (BODP) accounts for an architecture where data, metadata, software and infrastructure are bounded by ownership, including their cost consumption. Specifically in the context of FinOps, this means we want to aim for an architecture that makes it easy to control and monitor cost consumption with the right cost attribution.
A Cost Allocation Unit can contain:
The architecture quantum does not necessarily match a Cost Allocation Unit. In fact, several models can be found in real situations that put an Architecture Quantum in relation to a Cost Allocation Unit :
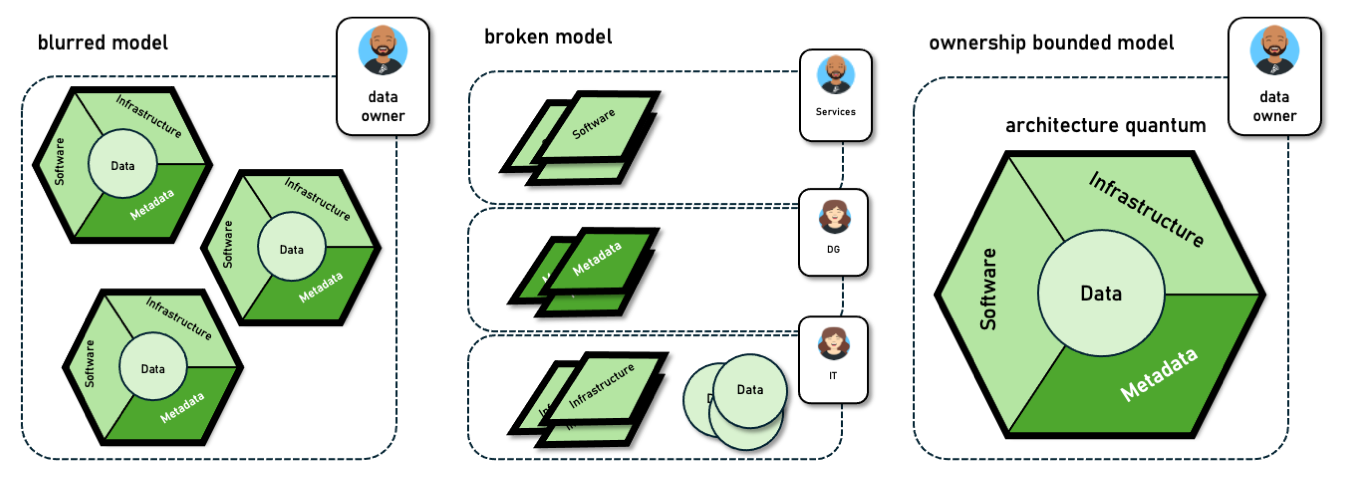
The ownership of data, systems (infra+sw), and costs do not necessarily match.
On the contrary, costs are usually attributed to IT departments while curation of data quality, data semantics, and lineage are assigned to stewardship roles implementing the DAMA framework. This configuration does not provide a direct attribution of cost to data stewardship roles and they are perceived as customers.
If you consider a Data Mesh implementation, you would probably like to bind data product teams with full ownership of systems, data, and metadata also including operational expenses. This is the typical situation for a broken cost attribution model. In general, an ownership model should account for data, metadata, systems, and their TCO.
_FinOps%20Architecture%20for%20Data%20Products.png)
This means that we must specify which kind of ownership we are talking about: ownership of things or ownership to run things.
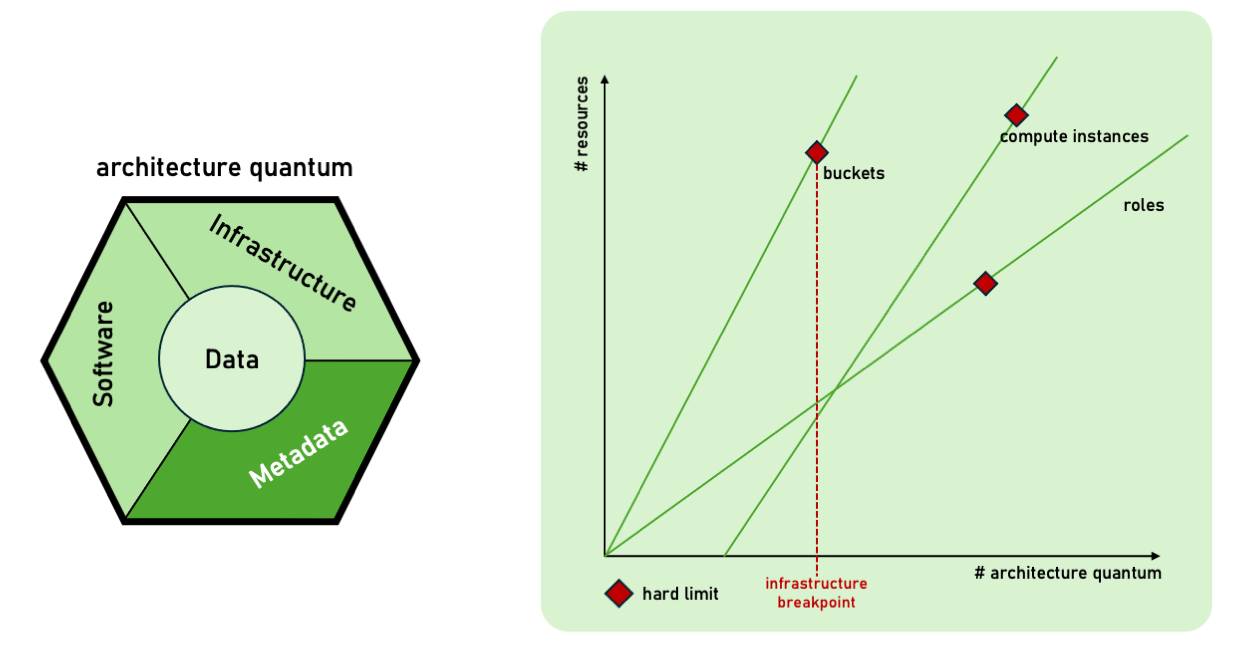
The ownership-bounded cost attribution model should aim at exclusive cloud resources for an architecture quantum. However, this is not always possible. One of the strongest limitations is given by the infrastructure breakpoint. As the number of architecture quanta grows, we should always check which hard limits we are hitting in the cloud infrastructure because they are going to determine the maximum population of architecture quanta sustained by the platform itself. Consequently, the platform design might opt for shared rather than owned resources.
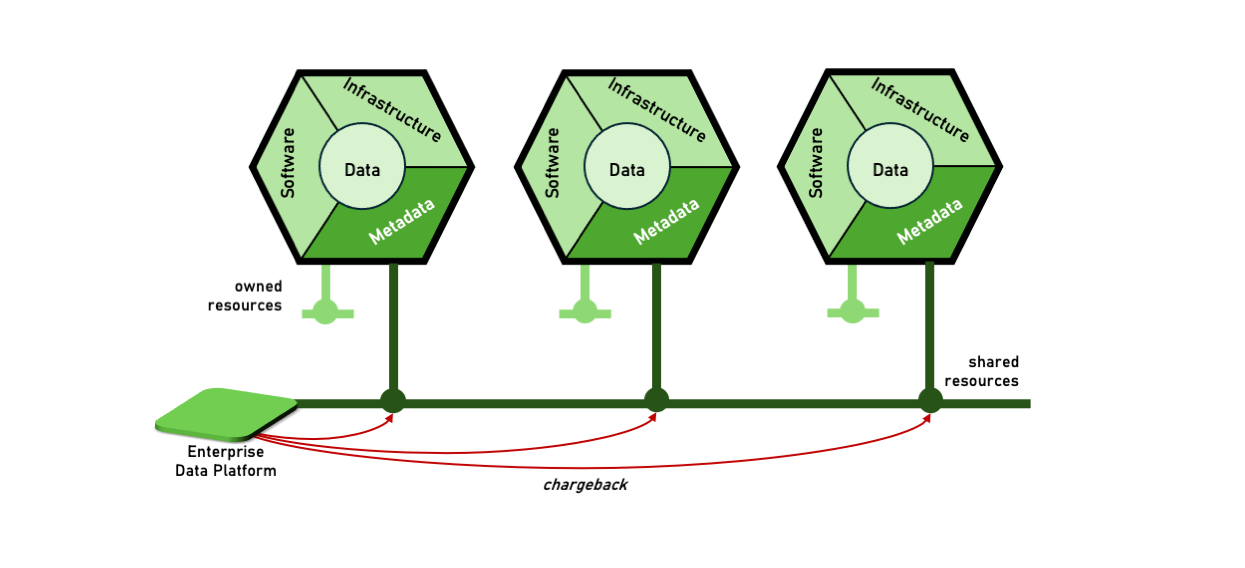
On average, an architecture quantum contains both owned and shared resources. Cost consumption for a Cost Allocation Unit can be determined by direct costs of owned resources and cost chargeback of shared resources.
A reference architecture to apply FinOps to a data management platform requires the following set of functions:
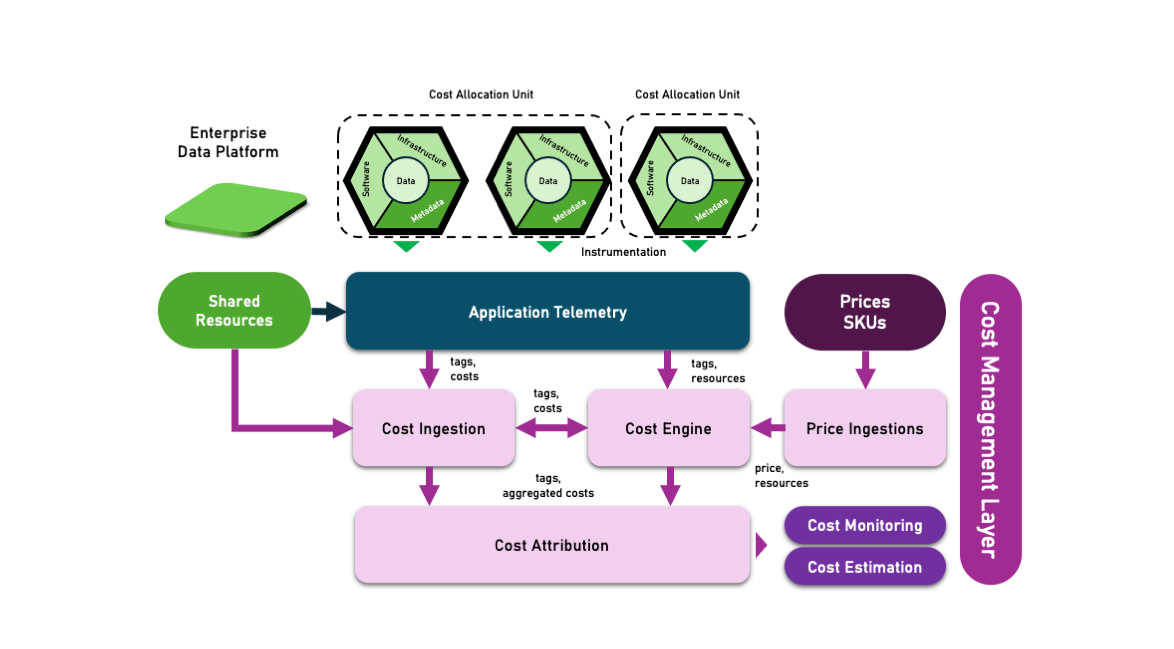
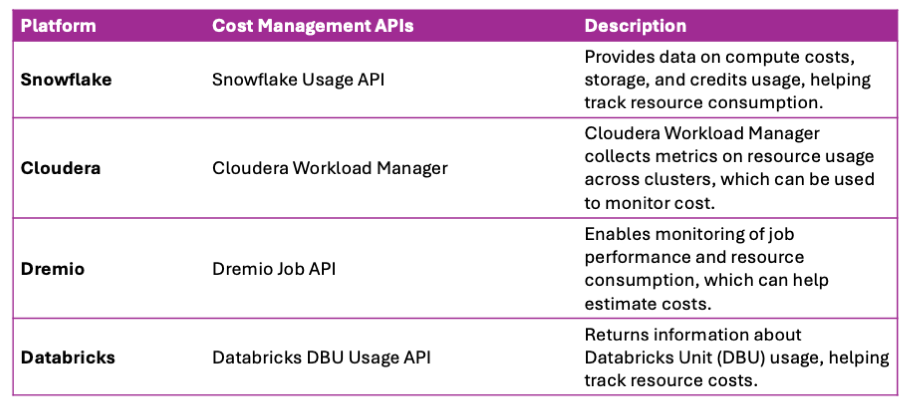

It looks like we have several levels of granularity from source to target-aligned tagging.
Depending on the definition of a Cost Allocation Unit for a specific company, tagging can follow different assignment policies:
Equal cost attribution:
Cost-weighted attribution:
Resource-weighted attribution:
As the reader can notice, this approach requires the Cost Engine to compute those artificial costs of CAUs based on heuristics. In fact, we are not measuring costs, we are formulating a cost attribution ourselves. The Cost Attribution module shall aggregate those costs through target-aligned tagging.
An architecture quantum is a data product that delivers a data model that makes sense to the business. This excludes temporary or technical tables, or intermediate aggregations or any piece of data that cannot be directly used as a product. Technical reusability is not a good reason to build a data product and this sets data products apart from regular data modeling for data lakes. A data lakehouse architecture usually has an ingestion layer to host raw data. Raw data mirrors tables from source databases and such representation does not necessarily work for the business and a certain degree of aggregation and denormalization should be applied.
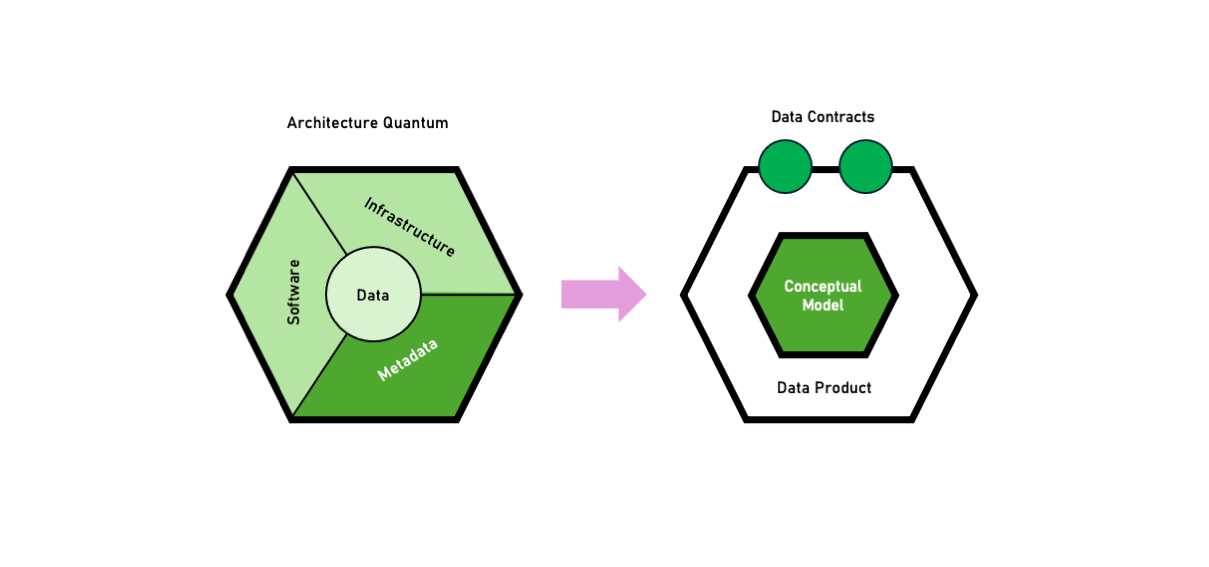
Product thinking requires a data product to guarantee a full certification process for data delivered. This certification process is provided by the data governance. Whenever this process is automated, we apply computational governance to data products. A data product provides the bounded context for a data model that can be delivered through as many output ports (aka data contracts) as the necessary data access patterns suitable for consumption (streaming, batch, interactive workloads). The relevance of data modeling in the cost management field is strongly underestimated but it is key to optimizing data reusability, while usually, software reusability is the major concern that brings to technical data modelling.
Data Products establish a clear ownership principle around a data model and everything necessary to make it consumable. This is strictly related to how we can implement cost attribution to build solid cost centers and charge-back policies.
This article proposes a reference architecture layout for FinOps applied to Data Product-based platforms. I’ve established a terminology to clearly define resource ownership and cost attribution models.
I’ve proposed the Bounded Ownership Design Principle (BODP) as an ownership principle that links the cost ownership between data and the respective metadata, software and infrastructure necessary to make that data consumable, while the Cost Allocation Unit concept represents the minimum unit of cost recognised by a company and this is specific for each company. Depending on the overlap between BODP and the Cost Allocation Unit, I argue that there are concerns about how cost attribution can be sufficiently granular to target a company’s goals.
This article addresses the consumption model between the platform and data products, while I’ve decided to keep the consumption model between data products out of the scope of this discussion most of the arguments can be repeated also in this case.
Learn the critical role of training in successful FinOps adoption, fostering collaboration, enhancing cost-efficiency, and maximizing cloud ROI.
Learn how to manage cloud costs effectively within a Data Mesh framework using FinOps principles and best practices.
Understanding the true essence of data products for effective decentralization and ownership.