FinOps
The Role of Training in Successful FinOps Adoption
Learn the critical role of training in successful FinOps adoption, fostering collaboration, enhancing cost-efficiency, and maximizing cloud ROI.
This article addresses FinOps from a Data Mesh perspective. If you have a desire to monitor and control your cloud spending over a Data Mesh initiative, well this is a good starting point.
Although FinOps is a holistic discipline for cloud cost management, I believe it is worth dividing and conquering a piece at a time to handle such a burden. Let’s bite the Data Mesh chunk first.
I started working on data mesh initiatives in this paradigm's early stages.
At the same time, I’ve also curated cost management as one of the pillars that a data platform must account for.
Modern data architectures often are Cloud-based and most of them are Cloud-native. It’s common to recognise a big lack of automated governance in big enterprises and most of the internal regulation is a mix of guidelines and directives without any real control. IT governance is often fragmented and left to common sense. Basically, IT governance at any level has a great lack of automation and this has as direct consequences missing monitoring and control of resources and spending.
The purpose of this article is to provide guidance for data leaders who want to sort out cost management in a data mesh initiative. This approach can be easily generalised to any kind of data management practice. My focus on data mesh arrives at a moment where this combination is basically unexplored. Generally speaking, Data Management and FinOps are not a very well-understood combination yet. FinOps aims to be a comprehensive financial discipline to manage cloud resources regardless of the specific context. On the one hand, Cloud spending is a single discipline, on the other hand, its amplitude is unmanageable if we don’t split the problem into multiple subproblems to solve. I want to address FinOps for Data Mesh in this article.
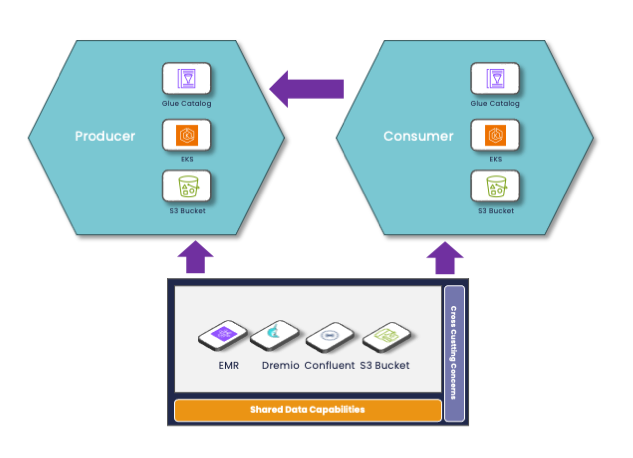
In a Data Mesh implementation, the self-service platform plays a key role in enabling data capabilities for data producers and data consumers to feed the marketplace of valuable data products.
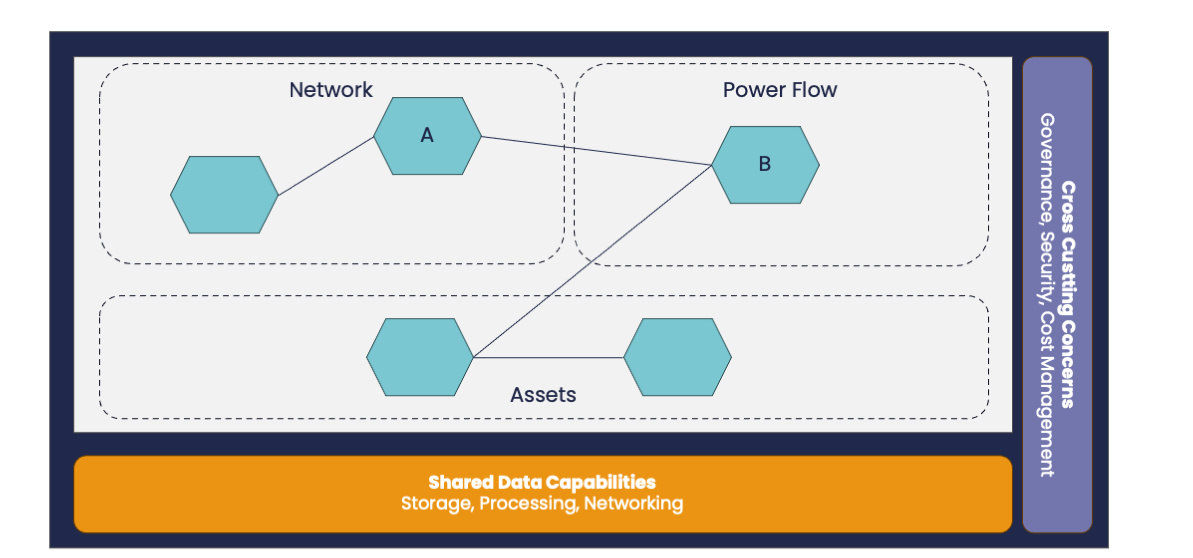
A Data Mesh Platform must provide cross-cutting concern capabilities (Security, Governance, Cost Management, Monitoring, etc.) and could provide shared resources like Kafka, or other resident clusters.
Data Products could either own resources or borrow shared resources from the platform.
Let’s stay on this high-level description. It is sufficient to discuss our FinOps challenge.
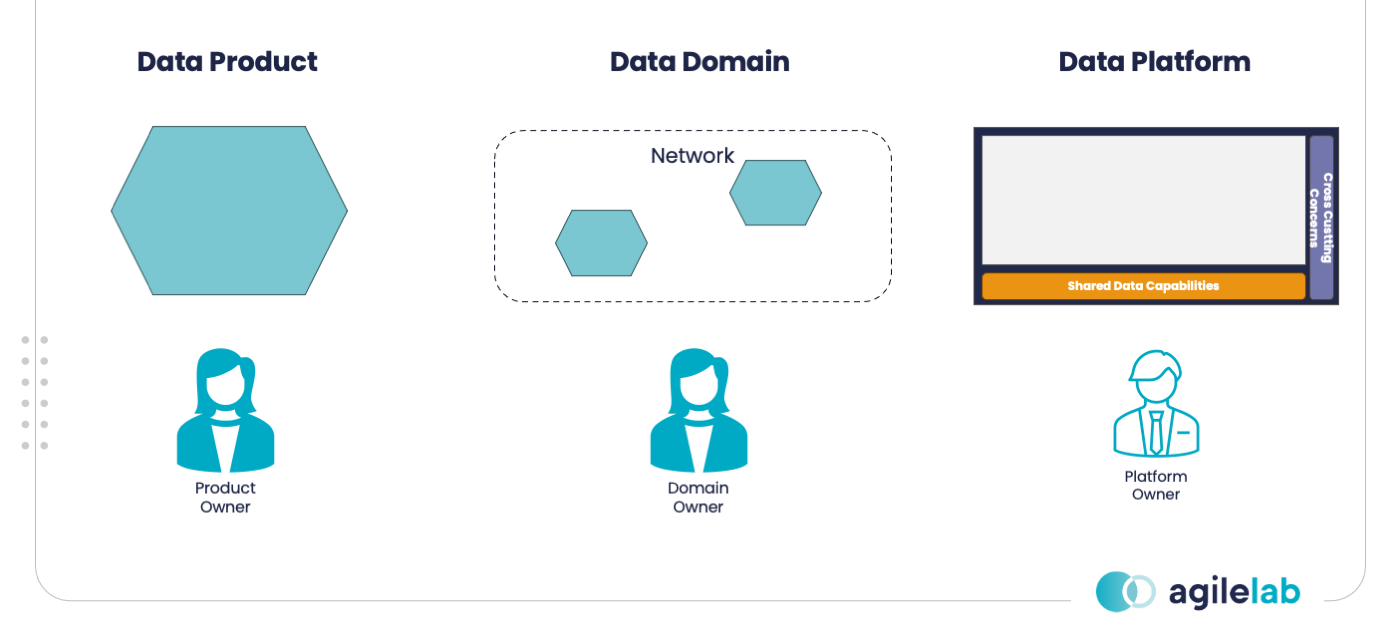
One of the benefits of Data Mesh is the adoption of a formal domain-driven ownership of data products.
It is reasonable to collect metrics at the Data Product, Data Domain and Data Platform levels. This allows Data Owners and Data Domains to determine their own spending and highlight dependencies to determine chargeback policies. The Data Platform team should access to everyone’s costs and provide cost management capabilities for Data Domains and Data Products.
For instance, having monthly cost updates provides feedback on how data have been produced with respect to consumption at the Data Product and Data Domain levels.
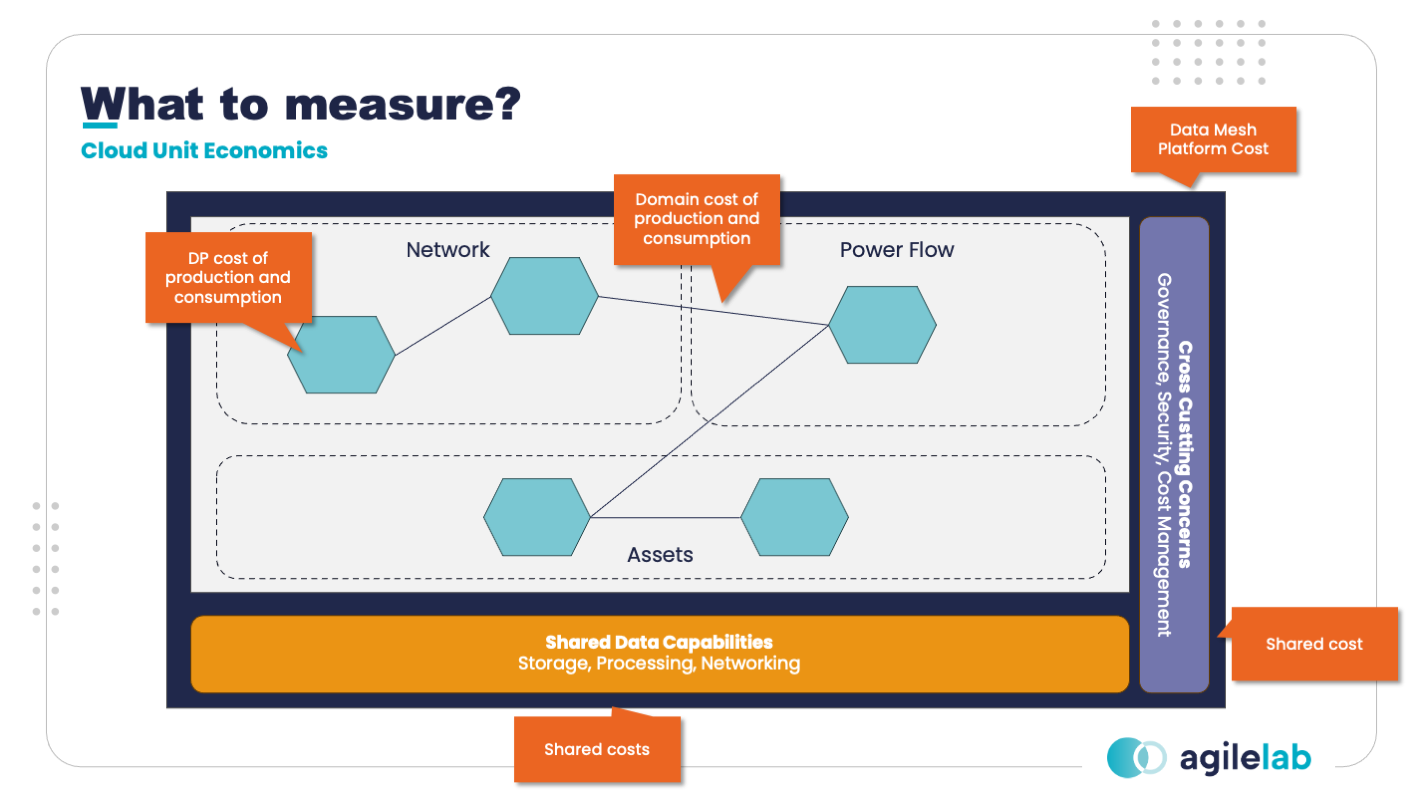
I’d start with a Data Product to understand how to decompose costs. But let’s introduce a definition of Data Product we can rely on.
A Data Consumer must be able to discover, understand, access, trust, safely use, and combine a Data Product with other Data Products. All the infrastructure, software and metadata necessary to provide Data Consumers with those guarantees make the Data Product.
For instance, Storage, Workloads, Data Contracts, Catalogues, and Data Marketplace are all components affecting the final cost of a single Data Product.

If you want to make money with a restaurant, you must first invest in a kitchen (CAPEX) putting people and materials. Once you have the kitchen, you want to run your business (OPEX) incurring in multiple costs: chief, cooks and raw materials are necessary to produce food, while waiters must carry dishes to clients (serving food).
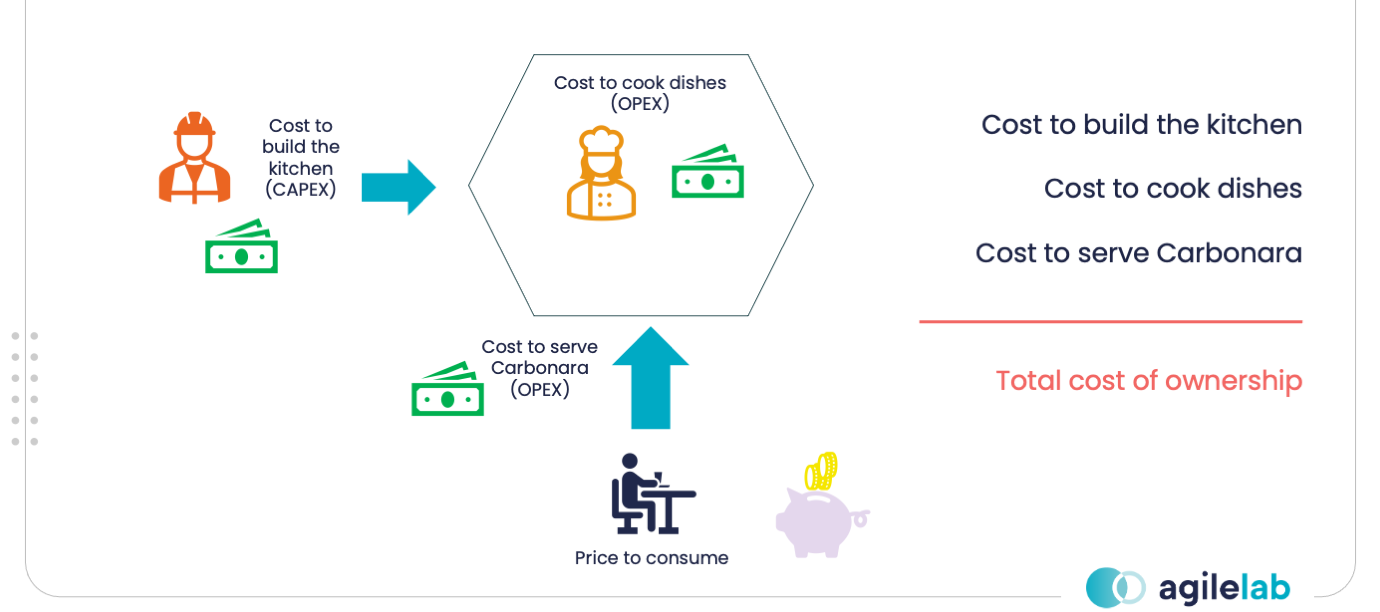
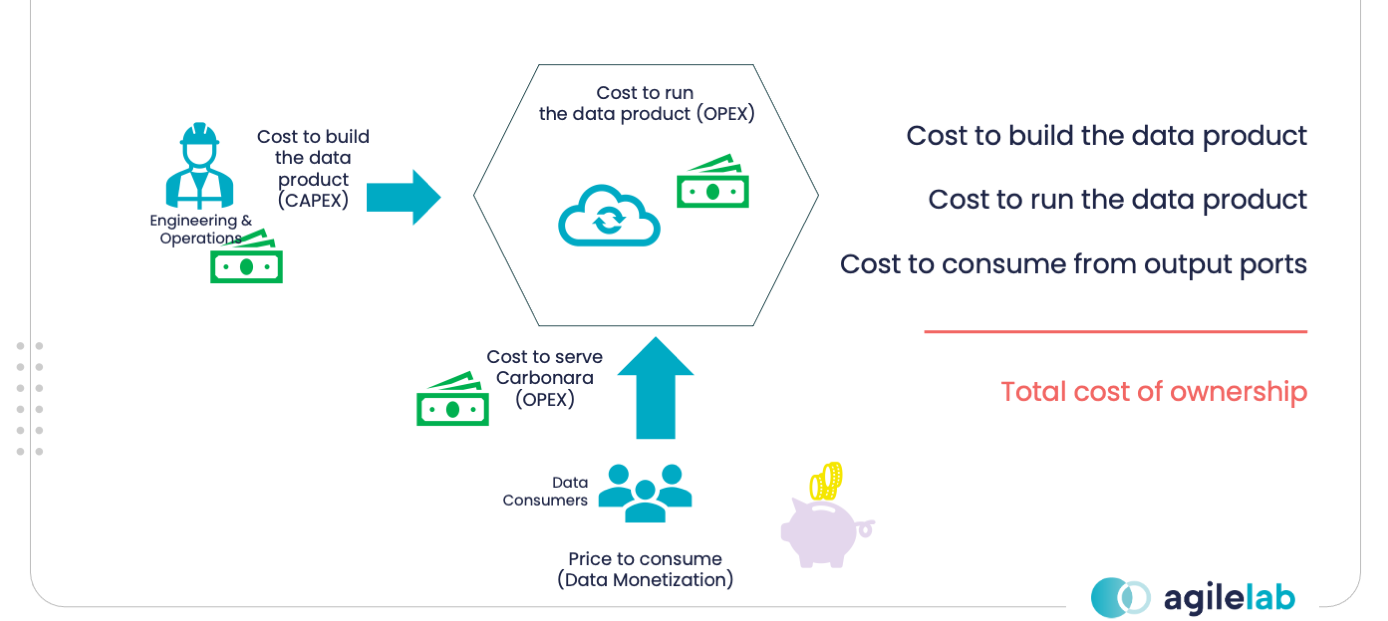
In the same way, a Data Product has a cost for building (CAPEX) and a cost for running (OPEX). The cost to run a Data Product can be split into the cost to produce data and the cost to consume data.
Data Production requires a live Data Product whose workloads generate data. The attribution of the cost of production is totally on the Data Product Owner. At the same time, this cost could be partially generated on platform-shared resources rather than owner resources.
Typically, Data Consumers access data from resources owned by another Data Product or shared with the platform. In both cases, a Consumer Data Product must be charged back for the portion of consumption of the used resources.
Tag Governance allows to associate specific labels to resources in order to aggregate costs based on the organization. This article supposes a domain-oriented organization where Data Products represent a relevant cost aggregation unit. Summing up the costs of data products, we should be able to directly obtain the cost per domain.
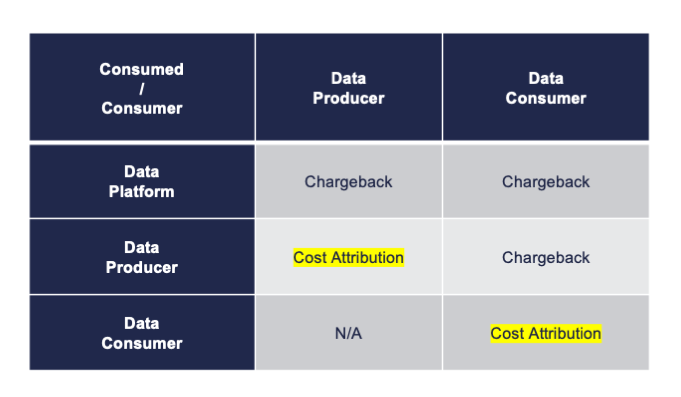
The resources owned by a specific data product can leverage the natural cost attribution provided by the data product itself, while shared resources must be charged back and there is a need for the definition of unit economics bridging the gap between the total consumption of a single shared resource and the consumption attributed to a consumer.
In the table above, cost attribution means that a data product can refer directly to the cost consumption provided by the cloud provider. Chargeback implies that we must collect information regarding resource consumption and formulate a link between resources and costs (so-called Resource Efficiency Unit Metrics).
Consider the following example. A data mesh platform provides the following shared resources for all data products:
Let’s explore the cost matrix for this example.
The Data Producer consumes resources from the Data Platform that must be remapped back to the Data Producer itself since directly associating those resources with its owner is impossible.
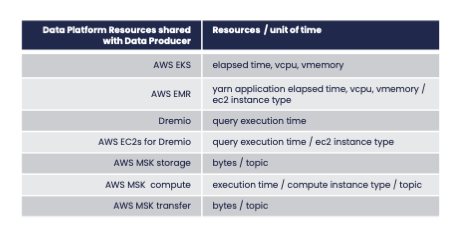
For instance, it is not necessarily trivial how to associate resources burned by a YARN application with a specific consumer in a YARN cluster shared among several use cases. This implies strong resource monitoring capabilities by the Data Mesh Platform to enable the remapping of these resource utilization to consumers.
A Data Consumer has access to the same platform capabilities and resources as the Data Producer. In addition, the Data Consumer needs to access resources owned by the Data Producer.
For instance, if an output port is based on a SQL view of a PostgreSQL owned by the producers, inquiries to the database will be charged to the producers. It is necessary to associate this cost back to the consumer.
As said before, resource monitoring is paramount for any data platform.
Resources to monitor depend on many factors including the business case. In the case of cost monitoring, we must ensure we are collecting all the metrics necessary to map costs to resources.
This requires engineering the right instrumentation of our services, meaning that the platform team must make shared platform services observable.
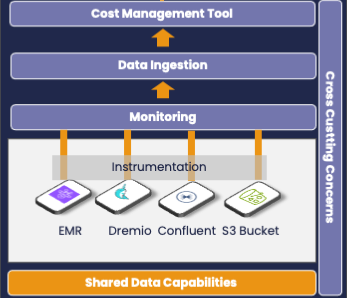
The monitoring architecture must be integrated with a cost management tool. In the context of FinOps this is called Data Ingestion (see for instance Apptio Cloudability Total Cost and Datadog):
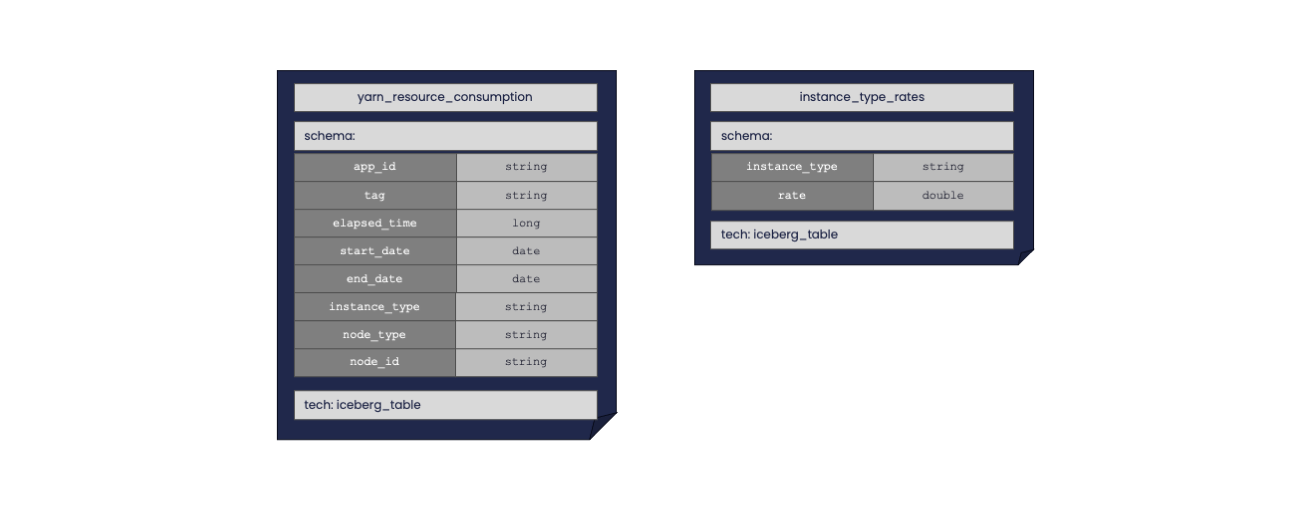
SELECT
yarn_resources.tag as tag,
SUM(y.elapsed_time * i.rate) AS cost
FROM
yarn_resources
JOIN
instance_type_rate
ON
yarn_resources.instance_type = instance_type_rate.instance_type
GROUP BY
yarn_resources.tag;
The same reasoning (with proper metrics) applies to the rest of the shared resources. Usually, cost management tools are able to ingest data and compute the right cost attribution starting from Resource Efficiency Unit Costs defined by the use case.
The Data Platform Team (or IT) should be represented by Domains and Subdomains as the rest of the company’s business areas. They should eat their soup by building analytics through Data products and enabling reasoning about cost management concerns.
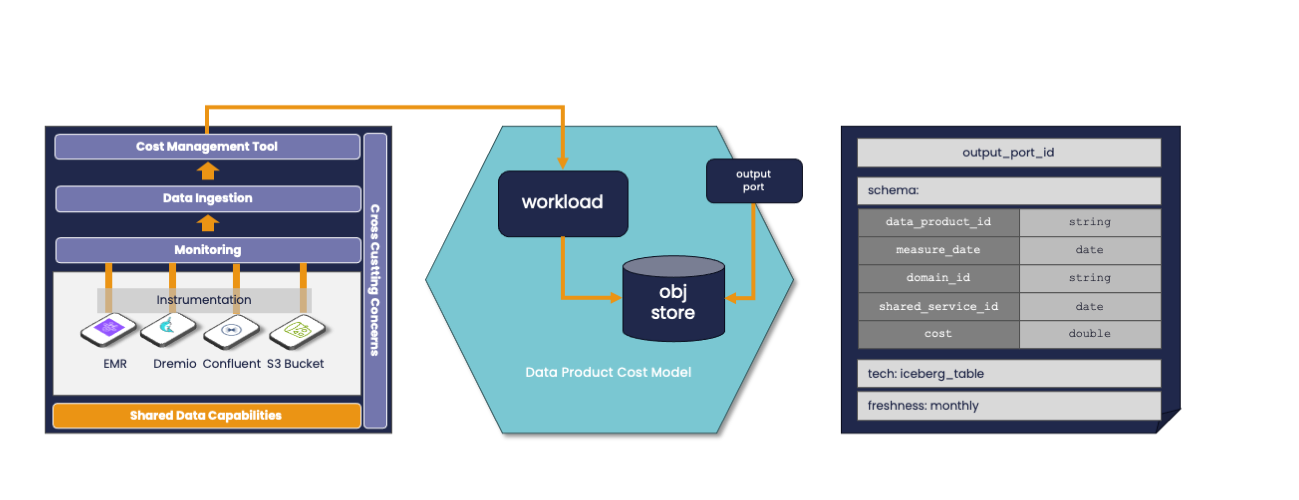
For instance, the Data Mesh domain (or IT subdomain) could be responsible for the creation of a Data Product that may address the following data model:
It is clear that a reusable Data Product can rely on multiple existing Data Products. In fact, this data model relies on other information that may be associated with a Data Product for Shared Services and a Data Product for Domains.
The Data Platform Team should find it beneficial to build other Data Products to enable several other departments. For instance, consider the following insights:
Through this information, it would be possible to address several optimizations:
Taking responsibility is a social attitude difficult to attain. An enterprise has as a primary purpose making money (and by luck having a social positive impact). Money is the main driver to impact on responsibilities.
A smoother approach would be showing back how much cost consumption is attributed to the client. But still, this is not moving the complete responsibility on the client.
Charging back triggers a mechanism of cost optimization and negotiation that improves the data value chain. In fact, consumers will fight to spend less, forcing producers to design cost-effective architectures. On the other side, producers and consumers will try to minimize misuse. For example, consumer data products will minimize the scheduled frequency of consumption to reach an affordable freshness of their data in agreement with the data contract (output port). Although showback is necessary to create awareness, chargeback is the real essence of the data value chain optimization.
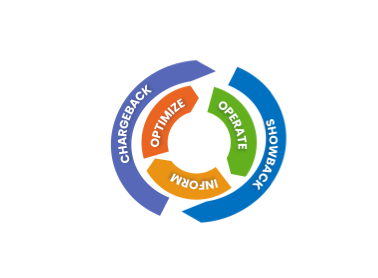
This is clear because while showback doesn’t imply any organizational change (at least, it’s not necessary or mandatory), chargeback could imply significant organizational changes since we are moving accountabilities.
Most companies do not apportion costs by domains, usually the IT department is a cost center responsible for the whole consumption and they are always committed to reducing costs for everyone. Since costs are not the responsibility of data practitioners, there isn't any culture of cost optimization. In the best cases, there is a good culture of performance optimization but cost and performance optimization are not exactly the same thing.
If data product owners were responsible for their own portfolio, they would report costs directly to the specific domain owner in charge of paying back the IT department.
%20vs%20Decentralized%20(Chargeback)%20Responsibility%20on%20Cost%20Optimization_Enabling%20FinOps%20for%20Data%20Mesh%2015.png)
This new tension between the IT department and data domains introduces the right balance between the need for spending (data domains) and the one for saving (IT department) making the whole mechanism more effective.
An important role of a Data Mesh initiative is the implementation of a mechanism of Federated Computational Governance. The decentralization of cost consumption accountabilities embraces the concept of federation. In terms of computational governance, a Data Mesh Platform should provide control and monitoring over cloud spending policies. But How?
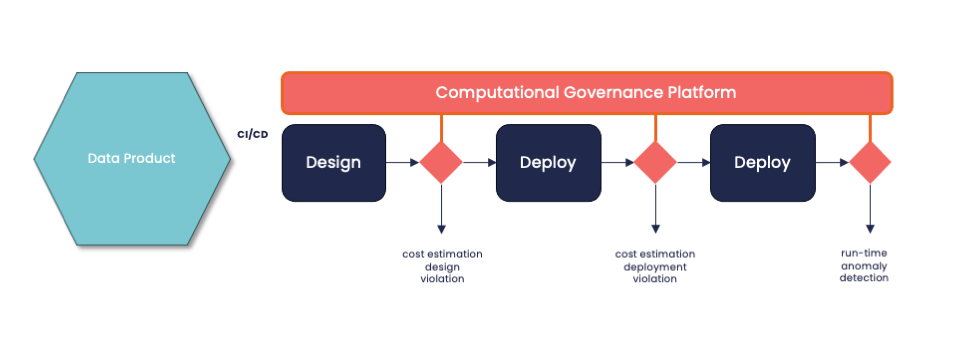
The Data Mesh Platform should embed a computational governance platform to enable the Federated Governance establishing company-wide cloud spending policies, such as:
Since we are talking about computational governance, policies must be coded and they run against metadata containing all the necessary information to evaluate the context. Usually, the data product descriptor is a metadata set associated with a data product that should be available for the computational governance platform. It contains information about architecture, infrastructure parameters, and data contracts, and can contain explicit cost estimations from the planning.
Although this article talks about Data Mesh, the same concepts apply to any other data management paradigm being it Datalake, Data Lakehouse, or DWH. Of course, since there is nothing trivial when applying a data management paradigm and FinOps, generally, there are multiple concerns to be addressed:
This contribution aims to enable practical reasoning on how to approach FinOps in a Data Mesh initiative:
I argue that most of the concepts apply to any data management paradigm and that team topology, data ownership, accountabilities on cloud spending and buy-in are some of the major concerns to start working on a sustainable cost management practice for a cloud-based data platform and data-driven organization.
Learn the critical role of training in successful FinOps adoption, fostering collaboration, enhancing cost-efficiency, and maximizing cloud ROI.
Explore a practical FinOps architecture for data products, focusing on cost control, ownership principles, and effective cost attribution models
Understanding the true essence of data products for effective decentralization and ownership.