Data Engineering
Practice Over Tools: Key Considerations for Data Engineering Project Development
Explore the importance of prioritizing practices over tools in data engineering projects.
Books, articles, blogs, conferences, etc. converge on clear ideas about data management, transformation, and storage. But when we talk about Data Engineering, what exactly do we mean? What is the approach to data management in today’s industry?

When we hear about Data Engineering, often what strikes us most is the emergence of new technologies and how quickly existing ones are evolving. The most simplistic and, let me say, obsolete view we still, unfortunately, have of this discipline is that of simple ETL programmers who move data from one side to another by executing optimized and fast complex queries. From this vision emerges the figure of the data engineer as a simple expert in data technologies who integrates complex systems to extract value from data, “supporting” data scientists.
According to a recent IDC survey, 80% of time in data management is spent on managing data instead of extracting value from it. The money left on the table is huge and if most of the companies find themselves in this situation it is because they are doing it wrong.
We need to re-invent the data management practice and we can only do it by re-engineering it. This is why we believe data engineering is not a professional role, but a business stream-aligned practice that should evolve drastically.
Data Engineering, as the word itself says, means engineering the data management practice; more precisely, we refer to designing detailed and challenged architectures, adopting methodologies, processes, best practices, and tools to craft reliable, maintainable, evolvable, and reusable products and services that meet the needs of our society.
Given the current difference between the various approaches adopted in the industry, at Agile Lab, we have introduced the concept of Elite Data Engineering to distinguish what Data Engineering means to us from our competitors. So, let’s try to understand what it actually means.
What is it that really distinguishes us from others in this area? What do we do differently?
In Agile Lab we want to elevate data engineering practices to a higher level, and we know we can do it by leveraging our hands-on experience across multiple customers and multiple domains. We always work with quality in mind and with a strategic approach, rather than a tactical one.
Over the years we have gathered knowledge and practices that led us to define some fundamental “pillars” to apply in different scenarios. Following the benefits our customers who rely on architectural solutions that are robust and evolve over time, addressing technical debt continuously as part of the delivery process.
Let’s try to understand, one by one, the pillars of elite data engineering better.
One of the main issues that causes people to spend 80% of their time managing data is the lack of data interoperability.
This leads to spending tons of time on data integration because there is no logical representation of the platforms and data. Every time data is needed, we need to understand where this data is physically located, and how to get access to it from an authorization and technical standpoint. We need to know what IP to target, which authorization mechanism to use, what driver to connect to the data storage, and whether we need to learn new skills. All these questions require time to be able to finally extract the data and examine it.
One of the challenges of data consumption is the lack of standardization and interoperability among various technologies and platforms. Moreover, there are no common processes and practices for accessing the data, as each silo has its own technical capabilities and limitations.
We have gained valuable insights from real-life use cases with different customers, across different domains and data volumes. We follow a set of technology-agnostic best practices that are not tied to a specific vendor but rather focus on delivering quality and evolving solutions for our customers.
To avoid technology lock-ins, we need to think about business requirements first, and then design high-level architectures that can be applied to different physical services. For example, after gathering business requirements, we create a logical data platform model that is technology agnostic. This model consists of a set of rules, constraints, and formal requirements that the physical implementation must fulfil. The next step is to implement processes that automatically transform this logical model into a physical one.
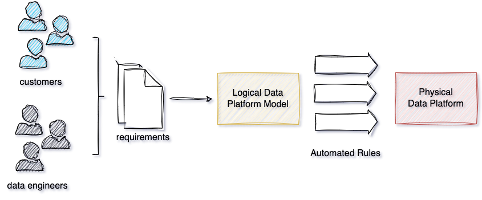
It’s not as easy as it sounds: imagine, for example, a team that specializes in Oracle, SAP, Cloudera, or any other platform. They will always try to adapt their solutions and processes to leverage the framework at its best, without considering the effects of some choices on the ecosystem.
Designing data architecture based on technology may seem like the fastest way to go, but it also comes with several risks: is this the best solution for the ecosystem? How much maintenance does it require? Is it adaptable? Focusing on decoupling and generalizing models, on the other hand, is important because technologies change, but practices evolve. Data engineers should be able to choose their preferred option from a basket of technologies that have a high level of interoperability at the data, system, and process levels.
To sum up, one of our values is “practice over technology”.
Interoperability and logical representations enable data integration with less effort, as they make data discovery and consumption across different technologies and platforms easier. When your platforms and data are logically represented, you can automatically access the underlying physical layer without knowing its details. This approach reduces the cost of data integration in data engineering projects and lowers the overall data management expenses.
Data engineers face a lot of cognitive load nowadays. They are not only software engineers, but they also need to master a variety of tools and practices to test, troubleshoot and operate data. They need to take care of testing and infrastructure in a way that is consistent with the data lifecycle, which is different from software. This excessive cognitive load is leading to a lack of productivity in their primary goal, converting data into business value.
Our way to address this challenge is by applying platform engineering principles to the data engineering practice. Platform engineering is the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations in the cloud-native era. By building platforms that reduce the cognitive load and provide ready-to-use developer experiences rather than technologies, platform engineering can create reusable and scalable facilities that can accelerate the delivery of projects and improve the overall efficiency for customers.
We are not talking about a specific technology here, but a practice platform that helps create a common workflow across different technologies and teams. This platform allows teams to share their methods and insights on how to deliver value from data. We envision a platform team that develops and promotes best practices and standards within an organization to improve the time-to-value of data projects. The platform team is technology-neutral and oversees the process.
The platform team offers various resources (such as templates) to the data teams with the goal to:
In a market where technology changes and evolves rapidly, we must always be ready to switch to better and more efficient solutions for data extraction. The innovation cycles are faster than ever and the competitive landscape in data management is constantly changing with new challengers surpassing old leaders.
However, when a large enterprise wants to introduce new technologies and platforms, it faces resistance from its legacy implementations because many tools and software are tightly coupled with outdated technologies. The ability to innovate is limited by the lack of design for it. If you don’t design systems for future innovation, you will not innovate. Innovation is not only a willingness but also a strategy.
One of our goals when we design a data platform is to make it durable for more than 15 years. To achieve this goal, we need to develop data architectures that can evolve with the changing technology. This is the natural outcome of our approach, as the logical data platform model is resilient to any technological changes.
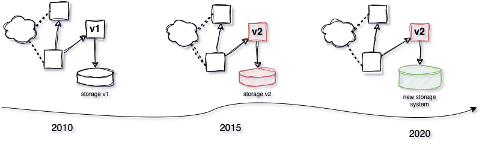
A common mistake here is to depend entirely on a platform and its built-in integrations and experiences. When designing architectures, an elite data engineer prioritizes system modularity, flexibility, scalability, openness, and component decoupling to support their evolution.
Data governance is a critical aspect of any data-driven organization. It ensures that data is accurate, consistent, relevant, and compliant with data protection laws. However, many data governance programs are ineffective, siloed, or outdated. They do not align with the data engineering lifecycle, and they create bottlenecks that slow down the delivery of data initiatives.
We believe that data governance should be shifted to the left, meaning that it should be integrated into the data engineering life cycle from the start. Data documentation, metadata, and data quality should follow the same life cycle as the code that generates them. Documentation is part of the business value that we want to deliver. Without it, data is not valuable, consumable, and understandable, so we cannot consider a project finished until it contains such an aspect.
Having ex-post metadata creation and publishing can introduce a built-in technical debt due to the potential misalignment with the actual data already available to consumers.
Data documentation should be accessible and self-explanatory, enabling data consumers to understand and trust the data they use. To support this, metadata must be generated before that data goes into production.
When we design a data platform’s logical model and architecture, we also link governance policies to the logical model (not coupled with technologies or platforms). These policies are not mere guidelines but integral parts of the platform’s definition. Data engineers have the responsibility to follow and comply with them and to automate their application from the start.
Shifting data documentation into the development lifecycle makes it versioned and machine-readable (metadata as code). This allows you to activate metadata to also create better data user experiences.
Building a data platform is a complex and time-consuming process that involves many architectural decisions and challenges. Manual implementation and maintenance can lead to errors, inefficiencies, and high costs. That’s why automation is essential for any data platform, but also any use case implementation.
Automation means applying it to every aspect of the data lifecycle: software and infrastructure deployment, data integration tests, continuous delivery, metadata management, security policies and compliance. Automation requires upfront investment in time and budget, but it pays off in the long run by reducing human effort and increasing quality and reliability. As Elite Data Engineers, we want to help our clients understand the benefits of automation and how to design data platforms and use cases that are scalable, adaptable, and future-proof, leveraging automation.
To achieve this, we always start from a machine-readable logical model. This way, we can use it to generate automations that are independent of specific technologies. A logical model is a high-level representation of the components, data, metadata, and their relationships, without specifying the technical details.
A high level of automation on deployments will free the data engineers from the tasks of thinking and implementing IaC, deployment scripts, operation procedures, etc.
Automation should also be applied to data testing by embedding integration tests on data, as part of the delivery process. Integration tests on data are a very challenging topic that must be addressed from the very beginning of a project to ensure no breaking changes in the data ecosystem will occur at runtime. Modelling what a breaking change means in the platform is an important step to keep data consistency at a large scale. Data Contracts are an important practice that we model and implement in our projects to enable full automation in data testing at deploy and run time, preventing breaking changes and data downtime.
Data security and compliance are often confused with data governance. Although they are not the same, they have some overlap: data security involves implementing mechanisms to protect data from unauthorized access, while data governance encompasses the activities to establish and enforce authority and control over data management.
Applying elite data engineering in this case means using automation: in fact, with automation you can ensure that your data security and compliance policies are applied automatically to your data. It is crucial to scan your data for vulnerabilities in an automated and systematic way so that sensitive data is detected before it is exposed unintentionally.
Having policies by design protects you from the risk of violating end-user privacy and regulations, which can be very damaging for a company in a time when we are all more concerned than ever about our privacy.
Vulnerability Assessment: It is part of an engineer’s duty to take care of security, in general. In this case, data security is becoming a more and more important topic and must be approached with a by-design logic. It’s essential to look for vulnerabilities in your data and do it in an automated and structured way to discover sensitive data before they go accidentally live. This topic is very important at Agile Lab, so much so, that we have even developed proprietary tools to promptly find out if sensitive information is present in the data we are managing. These checks are continuously active, just like Observability checks.
Data Security at rest: Fine-grained authentication and authorization mechanisms must exist to prevent unwanted access to (even just a portion of) data (see RBAC, ABAC, Column and Row filters, etc…). Data must be protected, and processing pipelines are just like any other consumer/producer so policies must be applied to storage and (application) users, that’s also why decoupling is so important. Sometimes, due to strict regulation and compliance policies, it’s not possible to access fine-grained datasets, although aggregates or statistical calculations might still be needed.
In this scenario, Privacy-Preserving Data Mining (PPDM) comes in handy. Any well-engineered data pipeline should compute its KPIs with the lowest possible privileges to avoid leaks and privacy violations (auditing arrives suddenly and when you don’t expect it). Have fun the moment you need to troubleshoot a pipeline that embeds PPDM ex-post, which basically gives you no data context to start from!
When it comes to data processing, we often mention specific technologies that suit our use cases. Choosing the right technology is a crucial step: we always try to maximize the potential of the technology to achieve optimal speed and scalability. However, this is not the only factor to consider, we also need to properly design data pipelines.
Our main principles are:
Decoupling: It has become a mantra in software systems to have well-decoupled components that are independently testable and reusable. We use the same measures with different facets in data platforms and pipelines.
A data pipeline must:
Also, it is essential to have well-decoupled layers at the platform level, especially storage and computing.
Reproducibility: We need to be able to re-run data pipelines in case of crashes, bugs, and other critical situations, without generating side effects. In the software world, corner case management is fundamental, just like (or even more) in the data one (because of gravity).
We design all data pipelines based on the principles of immutability and idempotency. Despite the technology, you should always be in a position to:
So far, we have talked about data itself, but an even more critical aspect is the underlying environments and platforms’ status reproducibility. Being able to (re)create an execution environment with no or minimum “manual” effort could really make the difference for on-the-fly tests, no-regression tests on large amounts of data, environment migrations, platform upgrades, and switch on/simulate disaster recovery. It’s an aspect to be taken care of and can be addressed through IaC and architectural Blueprint methodologies.
Performance: Performance and scalability are two engineering factors that are critical in every data-driven environment. In complex architectures, there can be hundreds of aspects that impact scalability and good data engineers should possess them as foundational design principles.
Once again, I want to highlight the importance of a methodological approach. There are several best practices to encourage:
Improved performances by design lead to reduced overall costs for resource consumption and positively impact the environment, reducing carbon footprint.
As just mentioned, reducing machine time using appropriate technologies and best practices lets us generate a positive impact on the environment.

For some years now, we have been witnessing climate change mainly due to pollution. This article does not aim to describe this global and serious problem. Instead, we want to focus on the fact that data engineers have a responsibility to contribute to reducing carbon emissions by minimizing machine-time and computing resources. This can be achieved by choosing the right technologies that are more efficient for specific use cases. But that’s not all! A smart use of cloud resources is also necessary to avoid waste.
The discipline of public cloud management adopted by companies with the goal of reducing waste is called FinOps. Essentially, it is a framework that consists of three main phases:
The logical model of a data platform also includes the information layer to activate the FinOps processes, providing visibility about the charge/show back model and activating all the automations needed to collect the billing information according to the logical model.
Our propensity towards extreme automation and interoperability allows us to apply and automate this practice in a comprehensive and cross-platform way.
Our solutions are always designed to create business value for our customers. We don’t just solve technical or architectural problems.
We use “product thinking” from the beginning.
Data cannot be managed as a project because it is a live process that is continuously evolving requiring maintenance, evolutions, and the discovery of new opportunities.
To overcome these challenges, an elite data engineer must adopt a product thinking approach, which means viewing their data assets and pipelines as products that serve specific customers and solve specific problems. Product thinking brings the focus on business value creation and shifts from a tactical mindset to a strategic one.
By applying product thinking to data engineering teams can:
Data engineering is about creating value for customers and users. By applying product thinking we can transform data assets into strategic differentiators that drive business outcomes and competitive advantages.
DataOps is the term that describes the set of activities, practices, processes, and technologies that aim to ensure data availability and quality, making it dependable and trustworthy. The name DataOps comes from combining “Data” and “Operations”, inspired by DevOps but with a specific focus on data management.
As elite data engineers, DataOps is a key concept for us because it incorporates the Agile methodology that has been part of our company culture from the start. It is an iterative cycle that aims to detect and correct errors in your data as soon as possible, with the goal of achieving a high level of reliability. Reliability means that we treat data issues the same way we treat software issues: we document them, understand the corrective actions (fix the pipeline, not the data directly), and conduct post-mortems. The pipelines must be idempotent to always produce the same outputs and must use data versioning.
Good reliability is closely linked to good data observability, since you cannot rely on or react to data that is not observable. This is important for enabling people to identify and resolve issues, as well as building trust in the data. The information provided by observability should be both contextual and up-to-date: contextual information is essential when troubleshooting data issues, as it helps to provide a complete understanding of the problem. Up-to-date data is equally important as it ensures that the information is accurate, which is key to building trust in the data presented.
Data versioning is another crucial aspect of DataOps: The observability and reproducibility issues are rooted in the ability to move nimbly on data from different environments as well as from different versions in the same environment (e.g., rollback a terminated pipeline with inconsistent data). Data, just like software, must be versioned and portable with minimum effort from one environment to another.
Many tools can help (such as LakeFS), but when they are not available it’s still possible to set up a minimum set of features allowing you to efficiently:
It is critical to design these mechanisms from day zero and make them part of the overall logical model to abstract such behaviour from the specific technological implementation.
All the topics covered in this article represent Agile Lab’s idea of data engineering. Acting like an elite data engineer concretely means following the pillars described above with consistency and coherence. These practices represent the starting points of elite data engineering, they are the result of the experience gained over the years and will certainly change and evolve in the coming years in line with the evolution of practices, society, and customer needs.
Explore the importance of prioritizing practices over tools in data engineering projects.
Learn how to manage cloud costs effectively within a Data Mesh framework using FinOps principles and best practices.
Unlock productivity & reduce cognitive load for data engineers with platform engineering. Streamline processes, enforce best practices, & automate...