Data Product
The Data Product Trap
Understanding the true essence of data products for effective decentralization and ownership.
In the context of data mesh, there’s a lot of confusion about how Data Products should be modelled. In a previous article, I provided basic rules for high-level modelling of data products, but here we’ll delve deeper and propose a completely new approach.
Note that these ideas are still in their embryonic stage and I haven’t had the opportunity to test them in a real environment. Nonetheless, I believe the reasoning can be valuable for those approaching this problem, and writing them down helps me crystallize and formalize them.
Within Data Products, specifically regarding how to model data in the output ports, I’ve seen two schools of thought.
One favours adopting an OBT modelling, with strong denormalization and data flattening, to facilitate data consumption without needing to resolve many joins, which typically require an understanding of the domain itself.
The other approach is to expose mini star-schemas as output ports to facilitate data modelling according to efficient logic without straying too far from the DWH world.
Both approaches have pros and cons, but most importantly, there is the issue of how to connect the data models of different data products and ensure that the potential consumer can do it simply, intuitively, and without falling into the classic challenges of dimensional modelling (loops, fan traps, etc.). Using a star-schema modelling inevitably means that many dimensions will need to be repeated in different Data Products, and each of these will polarize them differently according to their purpose. In fact, dimensions become such when opposed to facts, and in other parts of the global model, they could be facts. For example, there will be a customer registration business process, where the customer at some point materializes as a fact, but then the customer becomes a dimension when we talk about sales or shipping.
Data products by nature, following DDD modelling and trying to align with business domains, must necessarily contain facts that have occurred within business processes.
Some time ago, I came across the book “Unified Star Schema” (USS) by Francesco Puppini and Bill Inmon. Initially, I was a bit sceptical, but seeing Inmon’s blessing, I thought there must be something interesting, so I started reading it and was not only captivated by the linearity of thought behind this concept, but I also had the classic “wow” effect, like “how did no one think of this before?”.
While reading, I found many connections to the core principles of data mesh, such as the search for a better demarcation line between what contains a business requirement and what does not, with the aim of facilitating change management. The elements of enabling self-service logic are also very aligned with what we try to build in a Data Mesh, i.e., ensuring that those who hold business knowledge are entirely autonomous and independent in implementing their products without having to interface with IT or those who hold technical knowledge.
The key elements on which USS is based are:
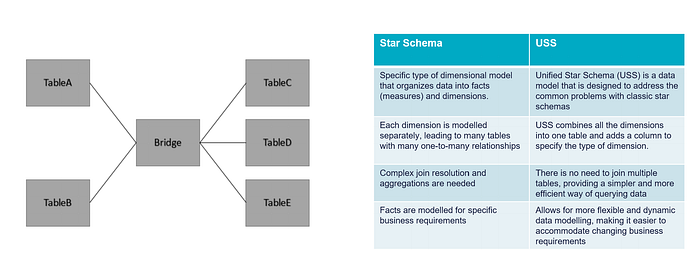
The main benefits are:
(Ref. Escaping SQL Traps with the Unified Star Schema — Show Me The Data)
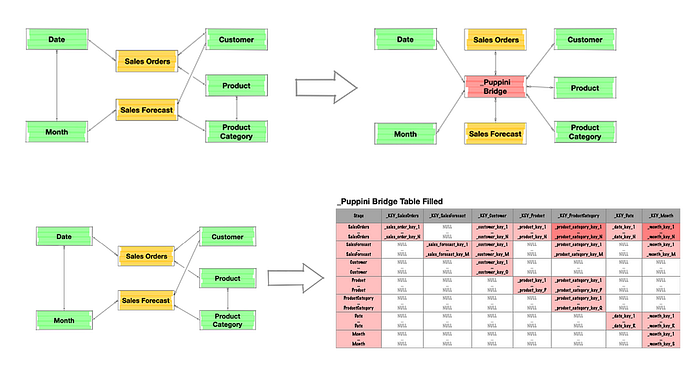
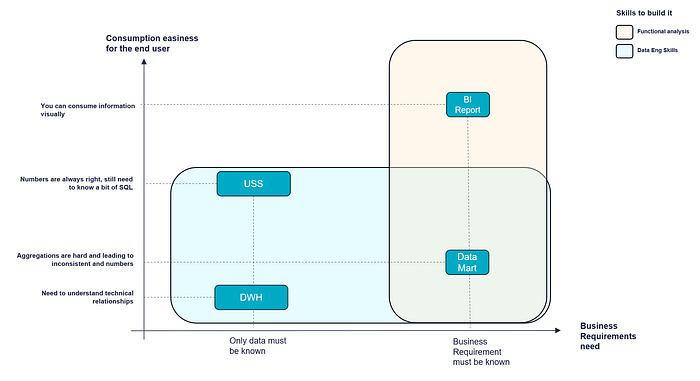
The most interesting part of this approach, in my opinion, is the search for a better compromise between data usability and the technical/functional skills needed to shape it. As shown in the following figure, the USS is positioned as simpler and more flexible to use model than a classic dimensional model, and additionally, it does not need to know the functional requirement at design time.
For more details, I refer you to the book and various articles by Puppini explaining the mechanisms and principles behind it (some of which I will revisit later in the context of Data Mesh).
How can a data mart modelling technique be useful in the data mesh context? We all know that the core principle of Data Mesh is domain ownership, which implies that the owner of a data product is in full control of the data they process and expose. Therefore, exposing a lot of data belonging (in terms of lifecycle) to another domain leads to strong misalignments, data quality problems, and difficulties in the consumption side of the entire mesh.
I will use a practical example to better illustrate the challenges and possible solutions. Let’s take the classic e-commerce business and analyse three crucial business processes:
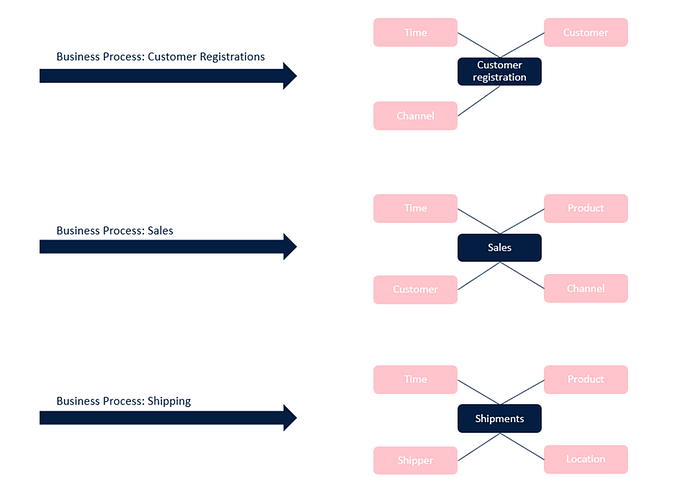
In a dimensional model, the data structure would have roughly this form (disclaimer: I am not a purist of data modelling, some PK is wrong, but this is not intended to be an exhaustive example, take it as a logical one).
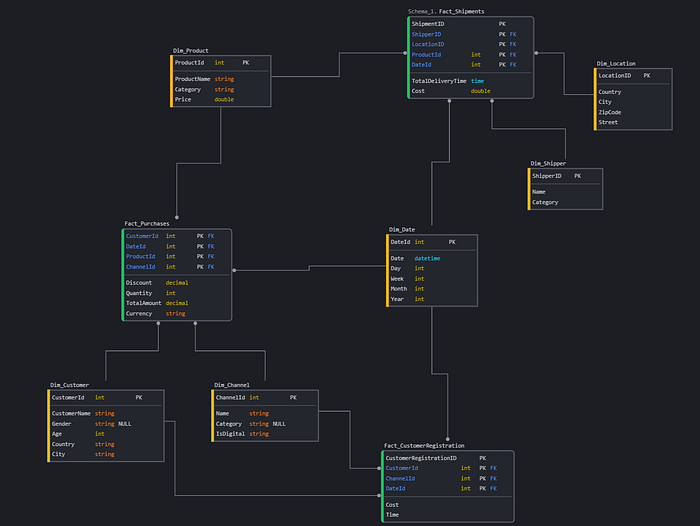
If we decompose everything based on business processes, we get the following:
In the Sales domain:

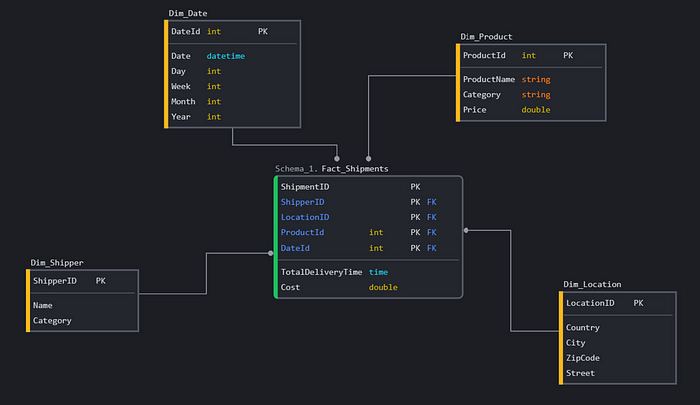
In the Shipment domain:
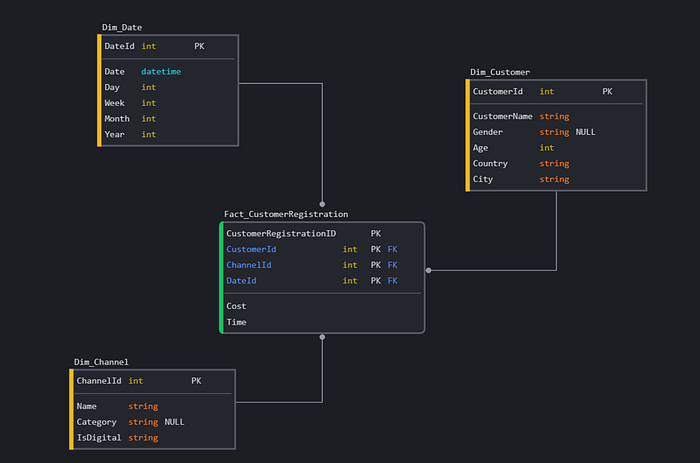
In the Customer Registration domain:
If we try to apply this data modelling technique into a Data Mesh environment, we find ourselves in the following situation:

The purchases Data Product needs to ingest data from the operational system but also needs to ingest data from the product and customer Data Product to reproduce the customer and product dimensions. This Data Product is clearly duplicating information pertinent to and originating from other Data Products. So, if we put ourselves in the shoes of a data consumer needing to conduct a complex analysis by joining customer, product, purchases and perhaps some other Data Product connected to customer like shipment, where will they get the customer information from? This complete information duplication does not facilitate the understanding of the overall data model and especially creates problems in terms of domain ownership — who will be responsible for the data quality of the customer if it is consumed through the purchases Data Product? Are we sure that purchases is not introducing distortions into the data itself?
The interesting aspect of USS is that by eliminating the concept of dimensions and converting everything to facts, we have a model that is intrinsically more aligned with the concept of data product. Remember that Data Products, if inspired by DDD, are equivalent to an aggregate, so they still represent a fact that has occurred within a business process.
If we try to model the previous case in USS, we get something like this:
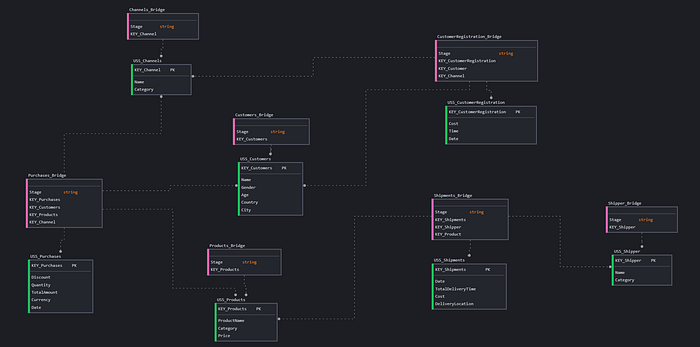
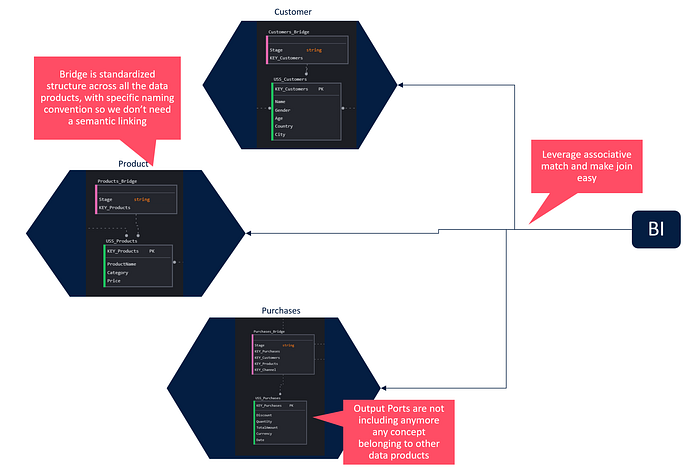
Here the novelty I am introducing is having not a single bridge but a bridge for each stage. The Puppini bridge is divided into stages representing bridge sections dedicated to a specific table or fact. Each stage represents the outgoing connections from a specific fact.
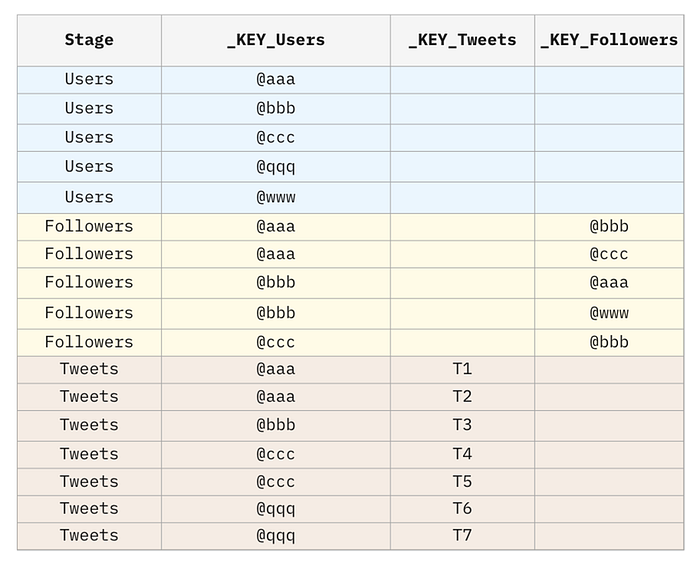
Having a single bridge in a Data Mesh implementation can create a huge bottleneck and also a conflict area where all Data Products converge. However, observing closely, it is also clear that this is easily partitionable. Therefore, I believe the more distributed approach, which better respects ownership principles, is to create a bridge for each Data Product, as shown in the previous representation.
Bringing it onto Data Products increases the clarity. The fact table becomes our output port, which will be completely devoid of information belonging to other domains. Within an output port, there are no foreign keys to other data products or information from other domains. This simplifies and cleans the interface for a user needing to analyse the specific facts.
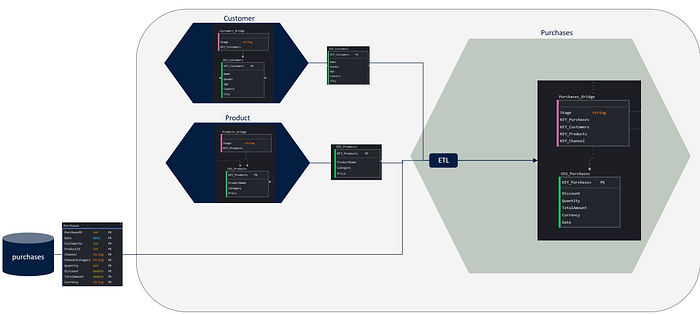
All relationships to other entities are confined within the specific bridge, and these are strongly standardized by the naming conventions of the Puppini bridge. This allows for very simple computational governance application both at deploy time and runtime. The standardization of relationship representation, within a context moving towards decentralization and greater automation, is a fundamental element (perhaps the most important benefit of USS).
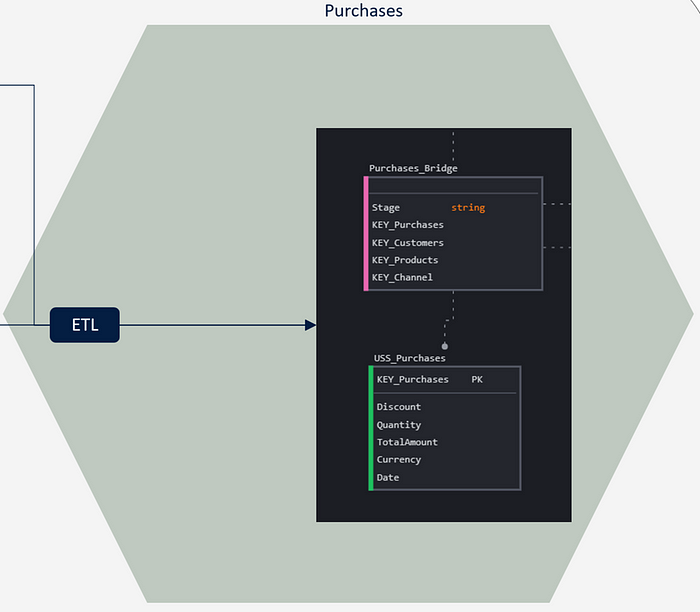
Observing this pattern from a consumer’s perspective, we must consider a few aspects.
When a consumer looks at a landscape of data products without USS, they need to understand how to resolve the joins (hopefully there will be a semantic layer to help with this, but I wouldn’t take it for granted in many companies), generating cognitive load and probably sparking conversations with the various data product owners to understand if the deduction on how to join the tables is correct. This creates a cognitive and operational barrier to true self-service consumption.
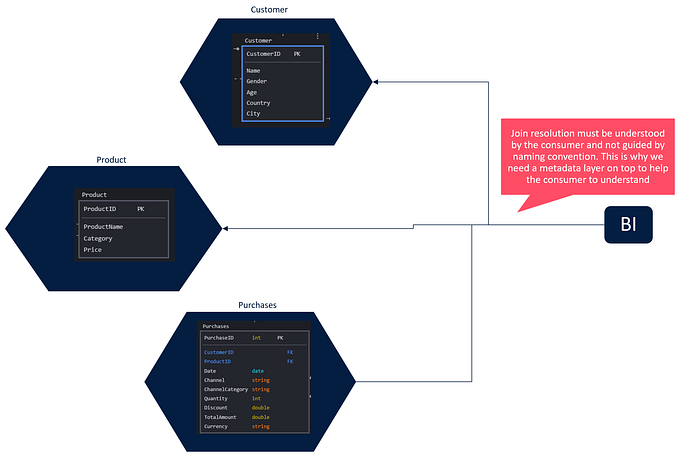
In contrast, USS becomes very functional for a consumer if leveraging tools capable of using associative logic to resolve relationships (exploiting the naming convention introduced by USS). Tools like PowerBI, BO, and many others already support this pattern, while if the consumer needs to extract data with Spark or similar tools, it is still very simple to build small frameworks that remove the complexity of the necessary joins to connect different data products. Understanding how the information should be joined cannot be wrong, enabling true self-service consumption and reducing users’ cognitive load.
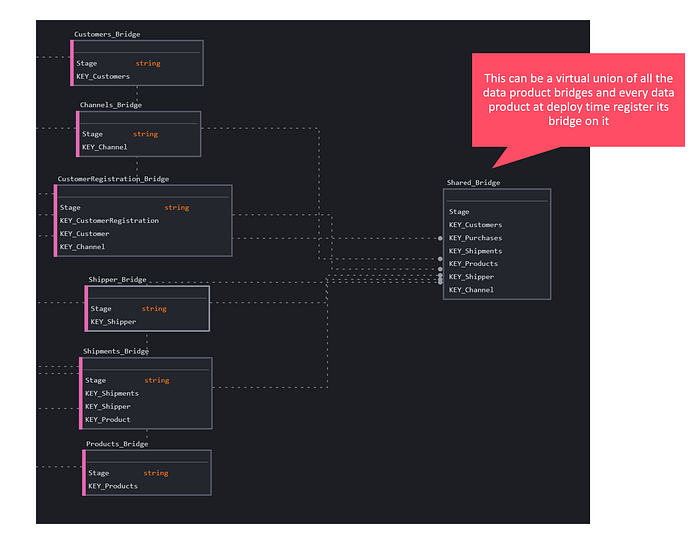
The other aspect to consider is how to recreate a single bridge in the eyes of the consumer, because this makes data model exploration much easier (especially on BI tools). What can be done is to create a virtual bridge that unions all the various bridges of the data products. Since these are standardized, automated, and verified by computational policies, it is very easy to keep the global bridge updated and aligned. Every time a Data Product is published (for the first or subsequent times), the platform will update the global bridge by modifying the global union statement and keeping it in sync with what is created in a decentralized manner.
Areas to explore with this approach:
Understanding the true essence of data products for effective decentralization and ownership.
Explore how the convergence of Data Mesh and ESG offers organizations a unique opportunity to drive sustainability and create long-term value.
Explore a practical FinOps architecture for data products, focusing on cost control, ownership principles, and effective cost attribution models