In the previous article, we started analyzing the individual features of Adaptive Query Execution introduced on Spark 3.0. In particular, the first feature analyzed was “dynamically coalescing shuffle partitions”. Let’s get on with our road test.
Dynamically switching join strategies
The second optimization implemented in AQE is the runtime switch of the dataframe join strategy.
Let’s start with the fact that Spark supports a variety of types of joins (inner, outer, left, etc.). The execution engine supports several implementations that can run them, each of which has advantages and disadvantages in terms of performance and resource utilization (memory in the first place). The optimizer’s job is to find the best tradeoff at the time of execution.
Going into more detail the join strategies supported by Spark are:
- Broadcast Hash Join
- Shuffle Hash Join
- Sort-merge Join
- Cartesian Join
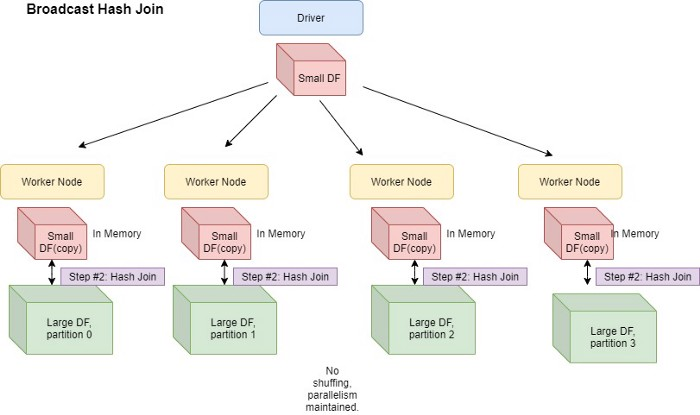
Without going into too much detail of the individual strategies (which is beyond the scope of the current treatment), the Broadcast Hash Join is the preferred strategy in all those cases where the size of one of the parts of the report is such that the broadcast table can be easily transferred to all executors and the “map-side” join avoiding the burden of shuffle operations (and the creation of a new execution stage). This technique, where applicable, provides excellent benefits in terms of reducing execution times.
Spark allows setting the spark.sql.autoBroadcastJoinThreshold configuration property to force the use of this strategy where one of the dataframes involved in the join is smaller than the specified threshold (the default value of the property in question is 10 Mb). Without AQE, however, the size of the dataframe is determined statically during the optimization phase of the execution plan. In some cases, however, the runtime size of the relationship is significantly smaller than the total size. Think of a join where there is a filter condition that at runtime will cut most records.
To better understand the potential of this optimization we will go to make a practical example. We will use THE public datasets of IMDB (also known as the Internet Movie Database) for our purpose. In particular, the film dataset (title.akas.tsv.gz) and the cast dataset.
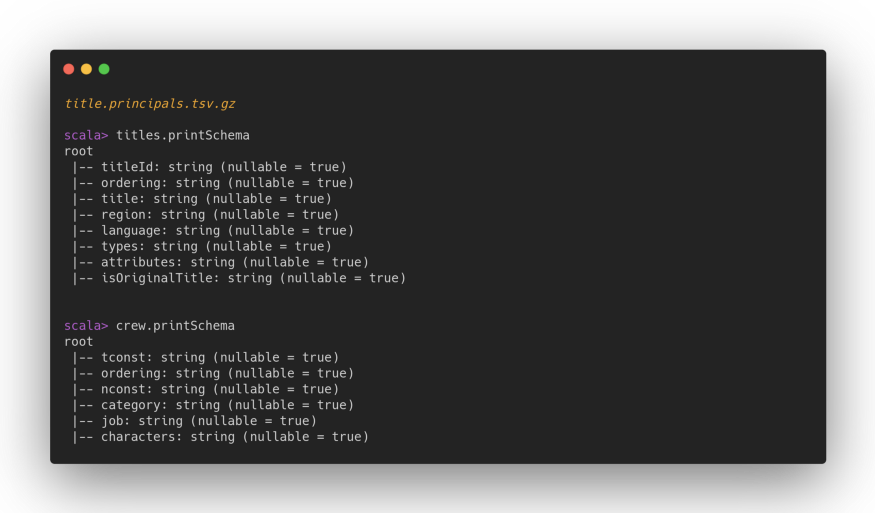
The dataset with the cast members is tied to the title dataset through the tconst field. The title dataset weighs about 195 MB and the cast dataset weighs about 325 Mb (gzip compression).
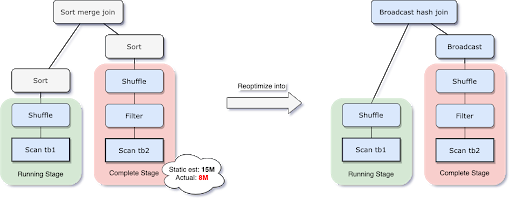
Leaving the default value for the broadcast limit threshold unmodified by trying to join the two datasets, the join strategy selected would of course be SortMerge. Without AQE even applying a very restrictive filter (for example, filtering the dataframe of the titles leaving only those related to the Virgin Islands that are very few) SortMerge would also be selected as a strategy. Try:
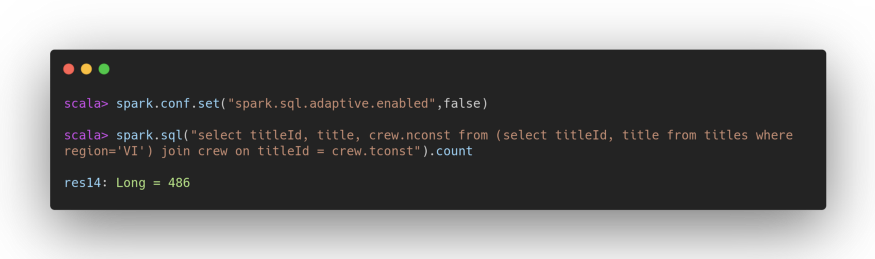
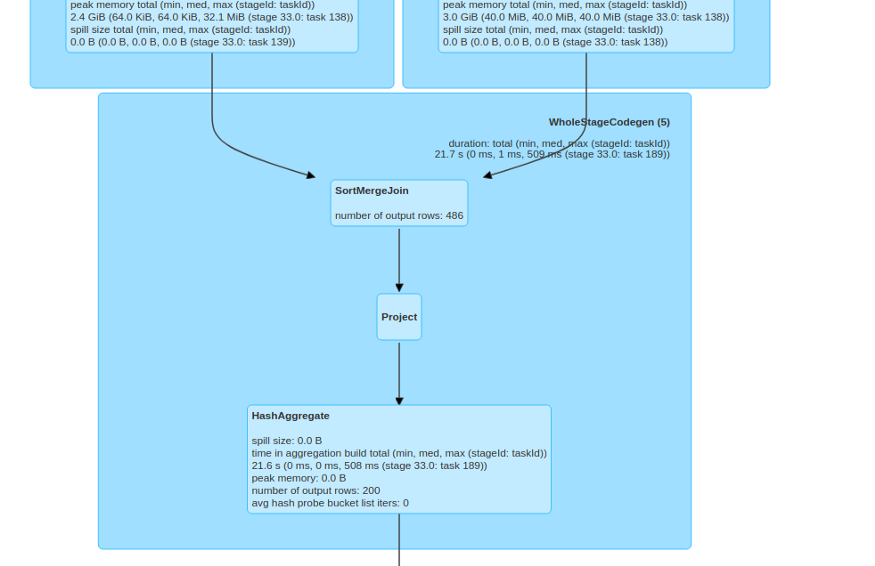
See what happens instead by activating AQE:
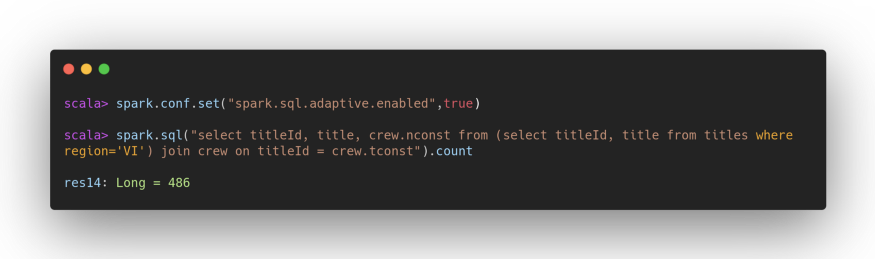
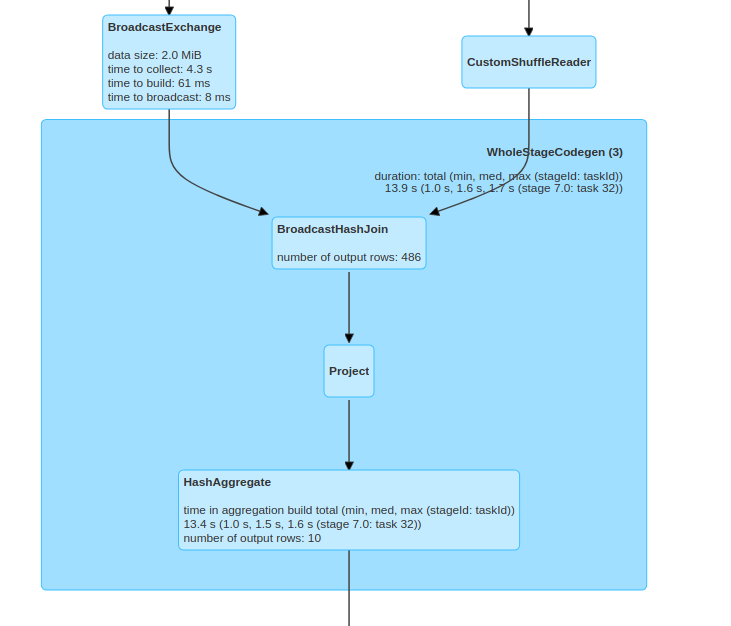
Thanks to the statistics calculated at runtime and the adaptive execution plan, the most correct strategy has been selected in this case.
The latest optimization, concerning dynamically optimizing skew joins, will be discussed in the last part of the article. Not to be missed!
Written by Mario Cartia – Agile Lab Big Data Specialist/Agile Skill Managing Director
If you found this article useful, take a look at our Knowledge Base and follow us on our Medium Publication, Agile Lab Engineering!