Skip to content
Witboost
Show submenu for Witboost
What is Witboost
Witboost Modules
Show submenu for Witboost Modules
Data Product Builder
Computational Governance Platform
Data Product Provisioning
Data Product Marketplace
Data Mesh
Success Cases
Resources
Show submenu for Resources
Knowledge Base
Events
Newsletter
Glossary
Company
Show submenu for Company
About Agile Lab
News
Partners
Media & Awards
Careers
Contacts
Witboost
Show submenu for Witboost
What is Witboost
Witboost Modules
Show submenu for Witboost Modules
Data Product Builder
Computational Governance Platform
Data Product Provisioning
Data Product Marketplace
Data Mesh
Success Cases
Resources
Show submenu for Resources
Knowledge Base
Events
Newsletter
Glossary
Company
Show submenu for Company
About Agile Lab
News
Partners
Media & Awards
Careers
Contacts
Be on top of your data game: Subscribe to our Knowledge Base!
Articles open source:
Real-Time Analytics in Mission Critical Applications For Usage Based Insurance
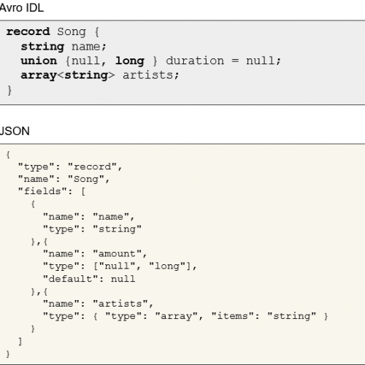
Darwin, Avro schema evolution made easy!
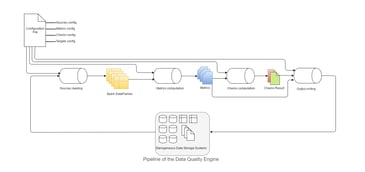
Data Quality for Big Data
Red Hat Open Source Day
WASP is now open source on GitHub!
Be on top of your data game. Subscribe to our Knowledge Base!